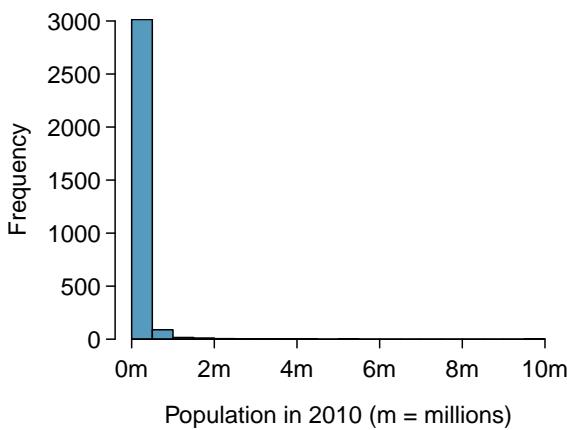
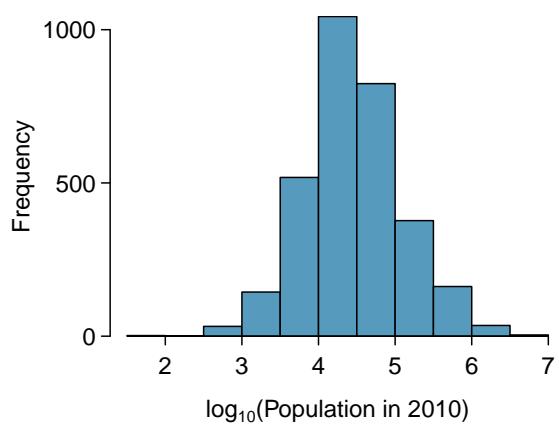
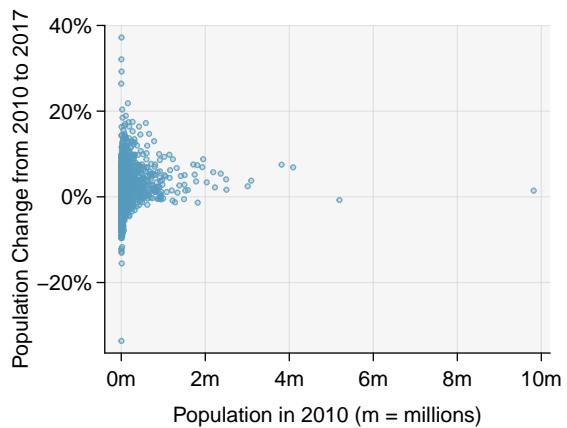
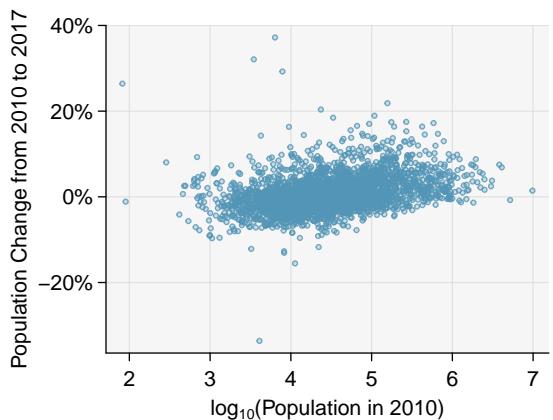
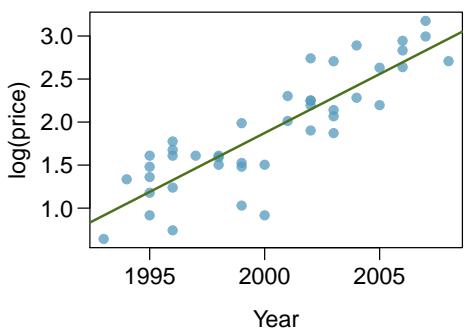
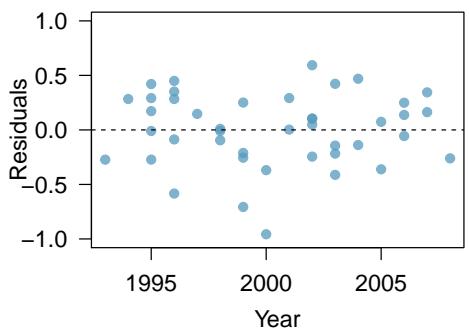
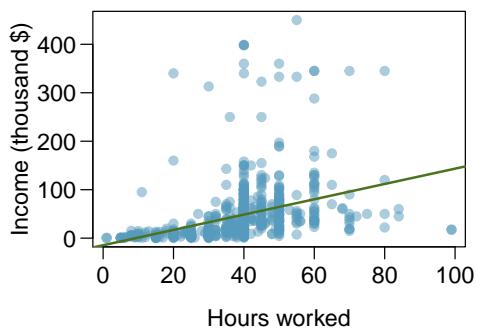
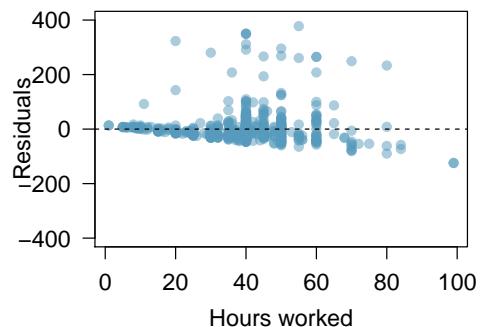
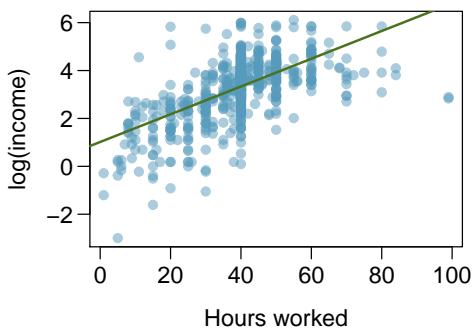
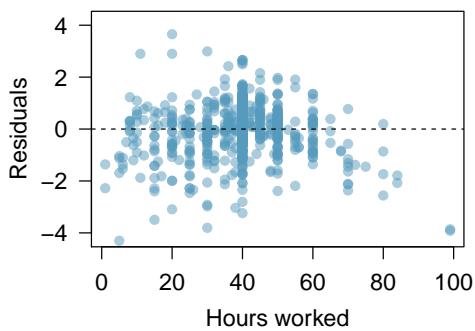
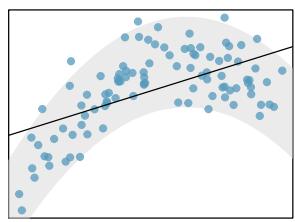
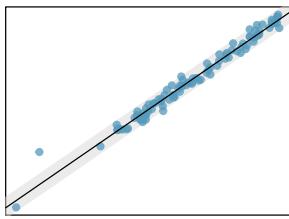
8.1 Line Fitting, Residuals, and Correlation
In this section, we investigate bivariate data — data collected on two numerical variables at once. We examine criteria for identifying a linear model and introduce a new bivariate summary called correlation. We'll answer questions like:
- How do we quantify the strength of the linear association between two numerical variables?
- What does it mean for two variables to have no association, or to have a nonlinear association?
- Once we fit a model, how do we measure the error in the model's predictions?
Bivariate data shows up everywhere in the real world — student test scores vs. study hours, medication dosage vs. blood pressure, family income vs. college aid. The whole game of regression is to turn "these two quantities look related" into "here's the line that best describes the relationship, and here's how much it misses by." Lines are the simplest possible model, and almost every more sophisticated model in statistics starts with a line as the baseline.
A linear model is a promise: "when \(x\) goes up by one unit, \(y\) goes up by \(b\) units on average." That single promise — a slope — is the most compact useful prediction you can make about two variables. The machinery of this chapter is about (1) when that promise is honest, (2) how to compute the best-fitting slope, and (3) how wrong the predictions typically are.
Learning Objectives
Source: Main Text
By the end of this section, you should be able to:
- 1. Distinguish between the observed data point \(y\) and the predicted value \(\hat{y}\) based on a model.
- 2. Calculate a residual and draw a residual plot.
- 3. Interpret the standard deviation of the residuals.
- 4. Interpret the correlation coefficient and estimate it from a scatterplot.
- 5. Know and apply the properties of the correlation coefficient.
8.1.1 Fitting a Line to Data
Requests from twelve separate buyers were simultaneously placed with a trading company to purchase Target Corporation stock (ticker TGT, April 26th, 2012). We let \(x\) be the number of stocks purchased and \(y\) be the total cost. Because the cost is computed using a linear formula, the linear fit is perfect, and the equation for the line is:
$$ y = 5 + 57.49 x. $$If we know the number of stocks purchased, we can determine the cost based on this linear equation with no error. Additionally, we can say that each additional share of the stock cost \$57.49 and that there was a \$5 fee for the transaction.
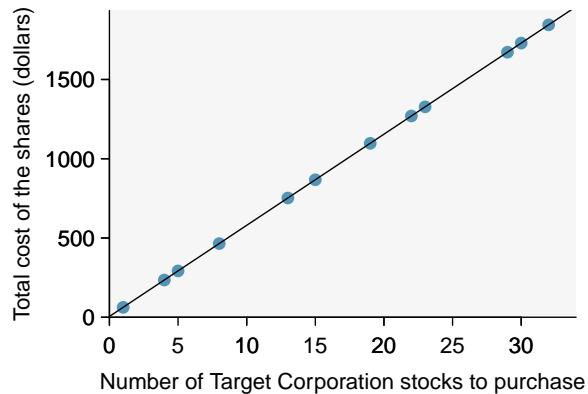
Figure 8.1: Total cost of a trade against number of shares purchased.
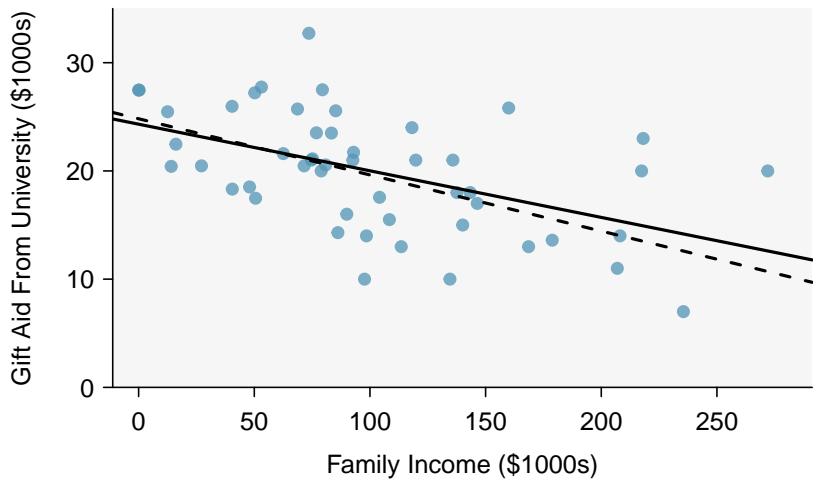
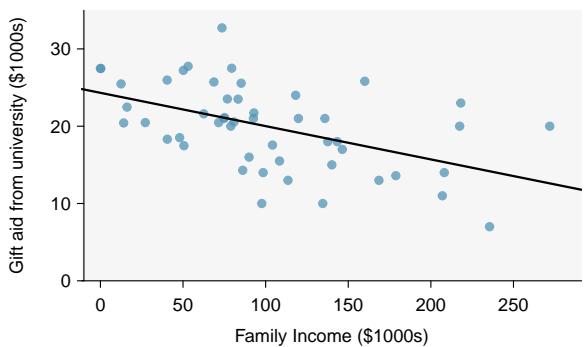
Perfect linear relationships are unrealistic in almost any natural process. For example, if we took family income (\(x\)), this value would provide some useful information about how much financial support a college may offer a prospective student (\(y\)). However, the prediction would be far from perfect, since other factors play a role in financial support beyond a family's income.
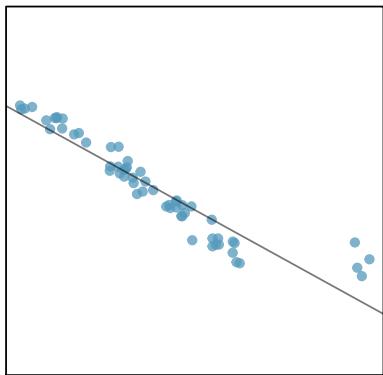
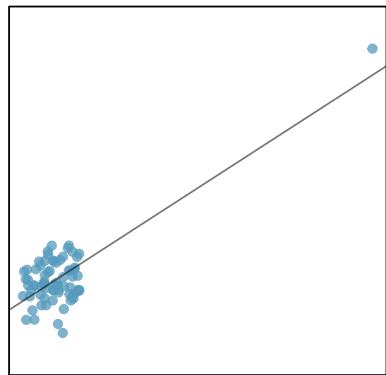
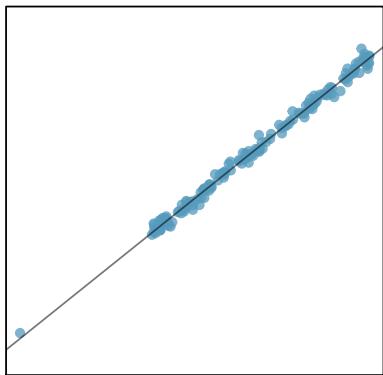
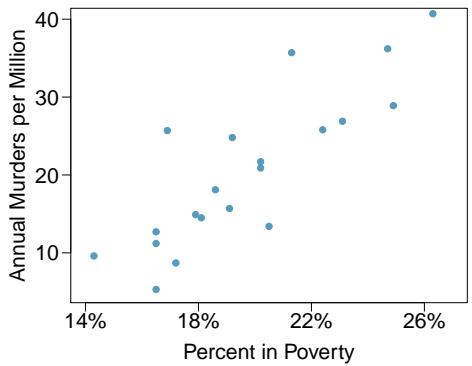
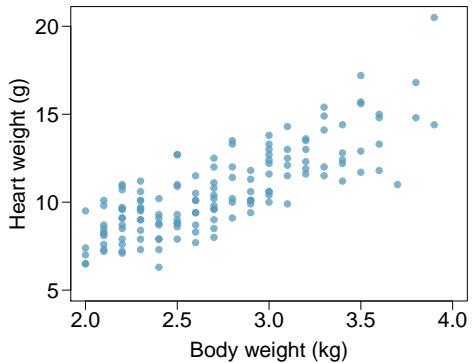
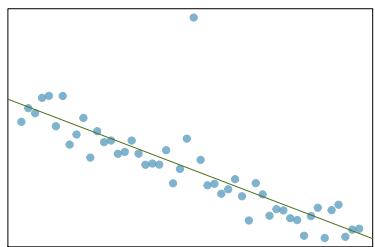
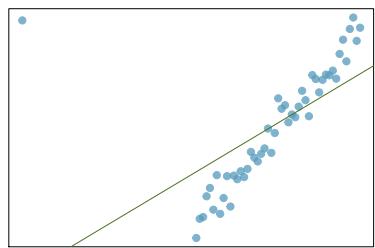
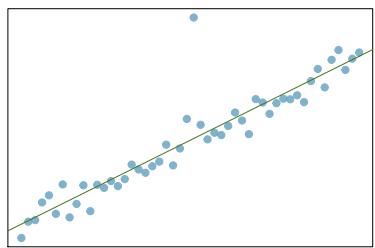
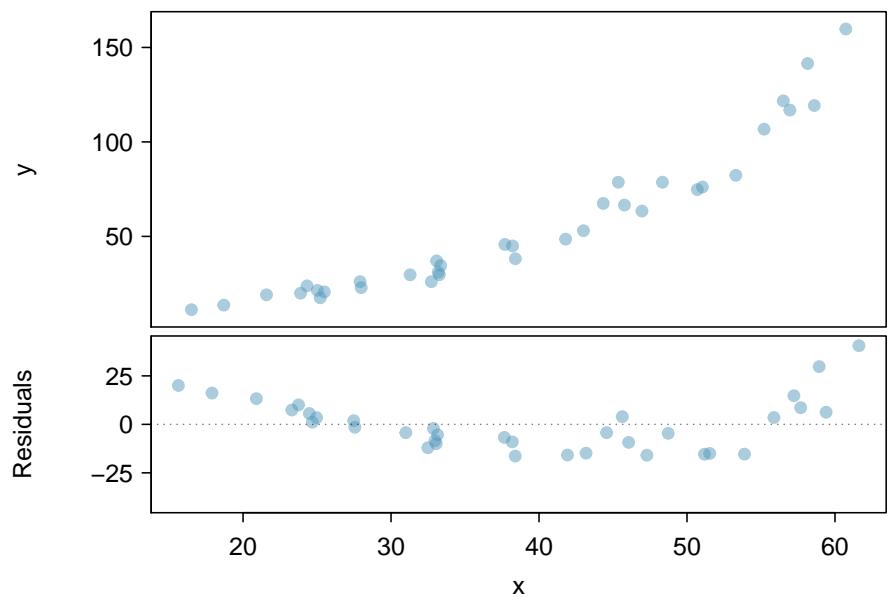
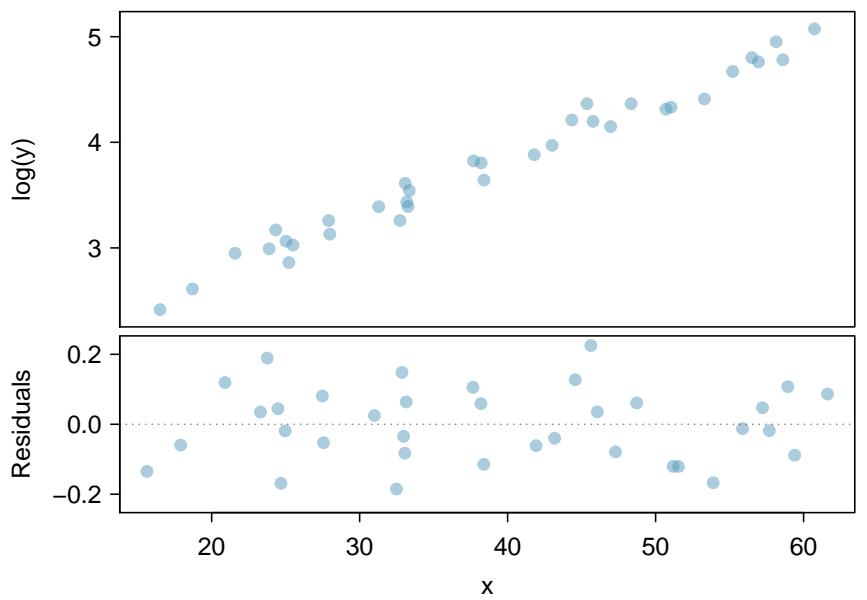
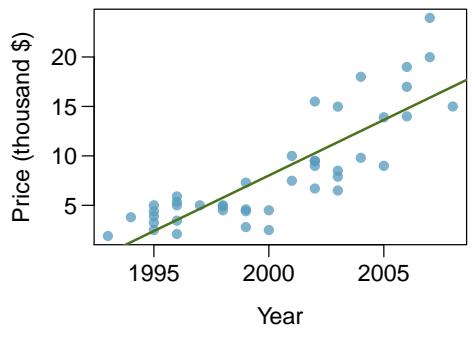
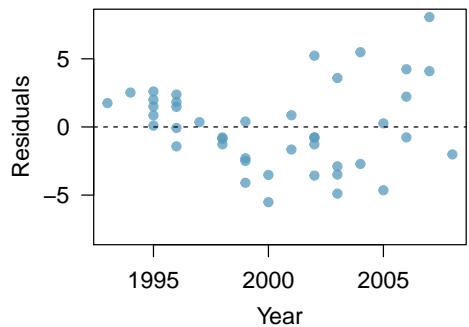
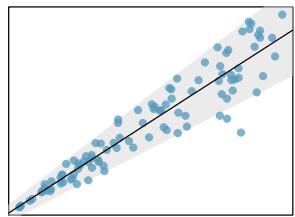
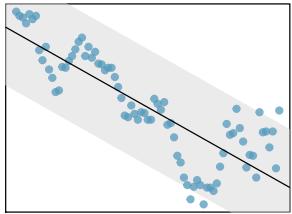
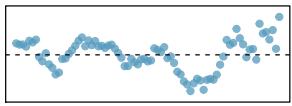
It is rare for all of the data to fall perfectly on a straight line. Instead, it's more common for data to appear as a cloud of points, such as those shown in Figure 8.2. In each case, the data fall around a straight line, even if none of the observations fall exactly on the line. The first plot shows a relatively strong downward linear trend, where the remaining variability in the data around the line is minor relative to the strength of the relationship between \(x\) and \(y\). The second plot shows an upward trend that, while evident, is not as strong as the first. The last plot shows a very weak downward trend in the data, so slight we can hardly notice it.
In each of these examples, we can consider how to draw a "best fit line". For instance, we might wonder: should we move the line up or down a little? Should we tilt it more or less? As we move forward in this chapter, we will learn different criteria for line-fitting, and we will also learn about the uncertainty associated with estimates of model parameters.
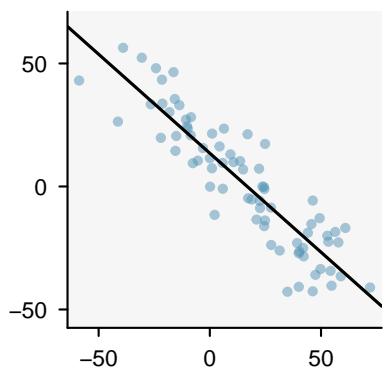
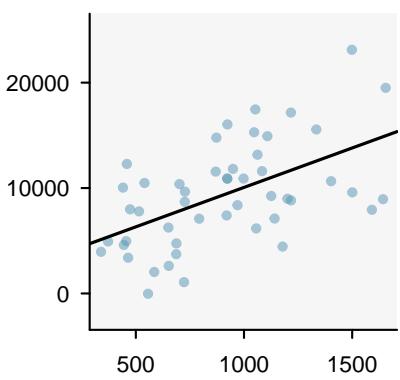
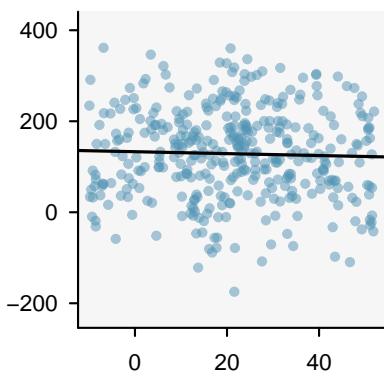
Figure 8.2: Three data sets where a linear model may be useful even though the data do not all fall exactly on the line.
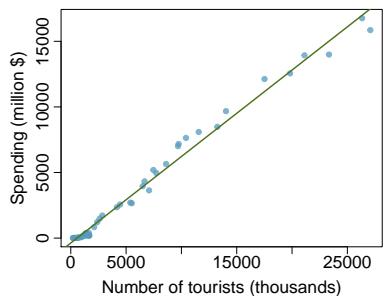
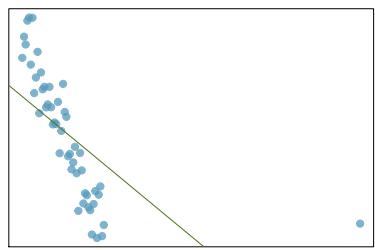
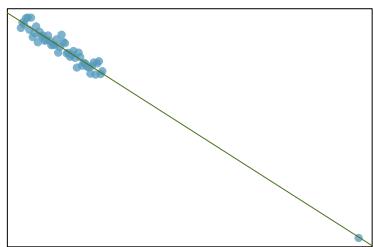
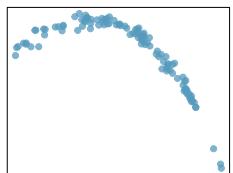
We will also see examples in this chapter where fitting a straight line to the data, even if there is a clear relationship between the variables, is not helpful. One such case is shown in Figure 8.3 where there is a very strong relationship between the variables even though the trend is not linear.
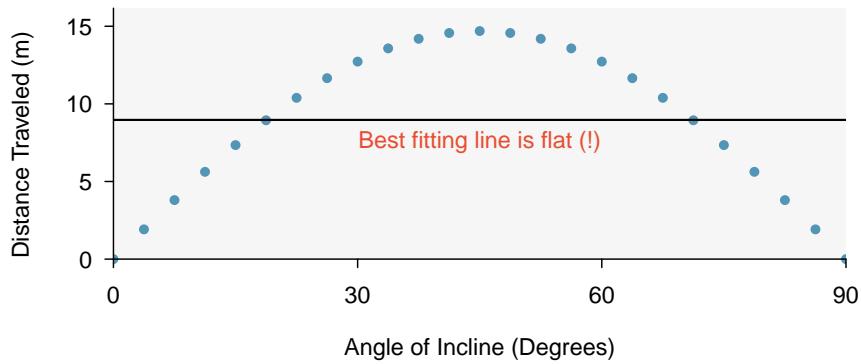
Figure 8.3: A linear model is not useful in this nonlinear case. These data are from an introductory physics experiment.
Almost any real data set has two competing stories: the underlying relationship and the random noise. When the TGT stock cost was computed by a formula, there was no noise — just the formula. But when we measure things in the world (heights, incomes, test scores) the same \(x\)-value produces different \(y\)-values across observations. Line fitting is the act of drawing the cleanest possible signal through that noise.
"Fitting a line by eye" is surprisingly good for getting a rough estimate, but it's also surprisingly inconsistent — ten students drawing lines through the same scatterplot will produce ten noticeably different lines. That's why statisticians eventually defined least squares as the objective criterion: among all the lines someone could draw, least squares picks exactly one, based on minimizing squared prediction error.
Source: Main Text
A coffee shop's daily muffin revenue \(y\) (in dollars) is given exactly by \(y = 2.50 x\), where \(x\) is the number of muffins sold. No fees, no discounts.
(a) If the shop sells 120 muffins, what's the revenue? (b) Does this relationship have any noise? Why or why not? (c) If a student went out and recorded one real coffee shop's muffin sales for 30 days, would you expect the relationship between muffin count and revenue to be exactly linear? Why or why not?
Solution
(a) \(y = 2.50 \times 120 = 300\) dollars.
(b) No — the relationship is defined by a formula, so every data point falls exactly on the line \(y = 2.50x\). There is no residual error.
(c) No — real data almost always includes factors that break a perfect formula: promotional discounts for regulars, day-old muffin markdowns, staff giving free samples, different prices for different muffin types. The scatterplot would still show a strong positive linear trend, but individual points would scatter around the line.
8.1.2 Using Linear Regression to Predict Possum Head Lengths
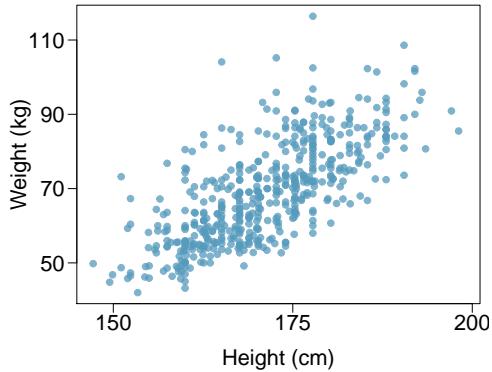
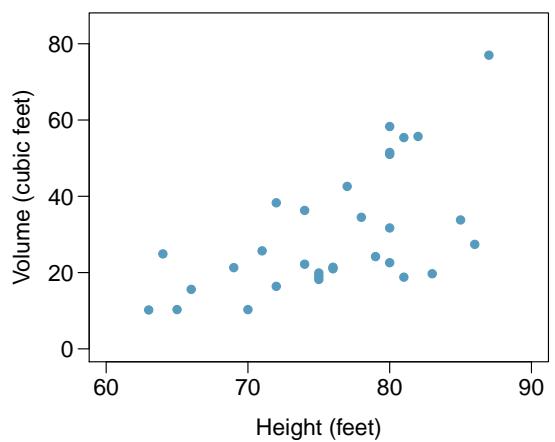
Brushtail possums are a marsupial that lives in Australia. A photo of one is shown in Figure 8.4. Researchers captured 104 of these animals and took body measurements before releasing the animals back into the wild. We consider two of these measurements: the total length of each possum, from head to tail, and the head length of each possum.
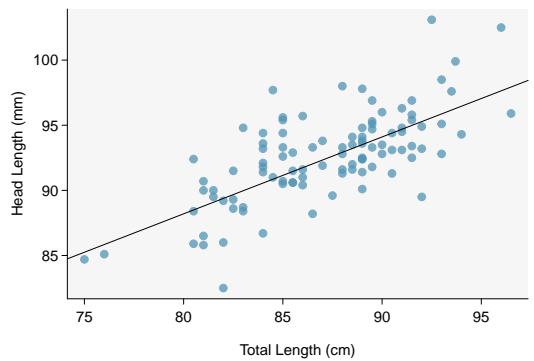
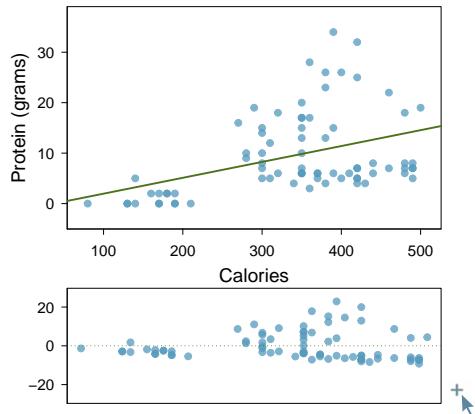
Figure 8.5 shows a scatterplot for the head length and total length of the 104 possums. Each point represents a single observation from the data.
Figure 8.4: The common brushtail possum of Australia.

Photo by Peter Firminger on Flickr: http://flic.kr/p/6aPTn CC BY 2.0 license.
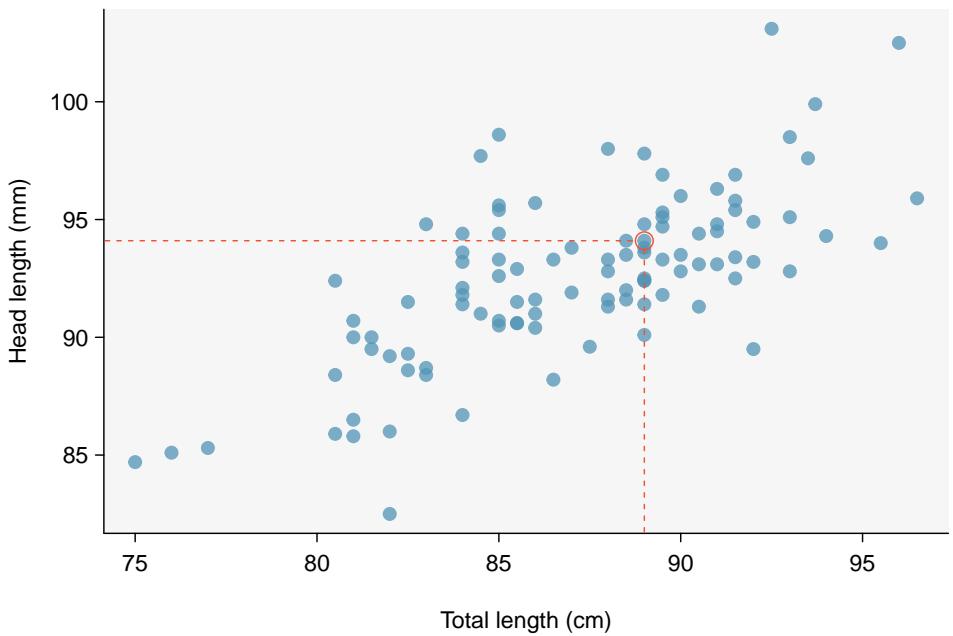
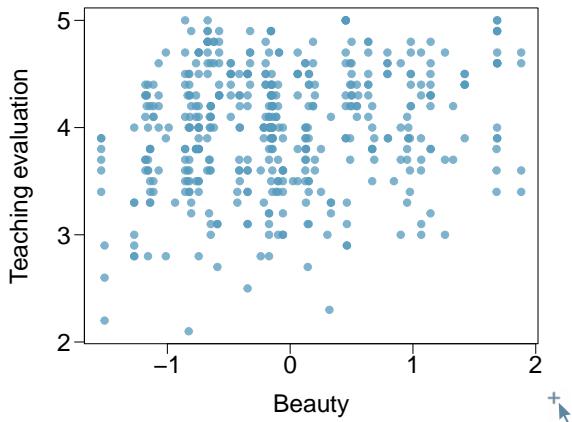
Figure 8.5: A scatterplot showing head length against total length for 104 brushtail possums. A point representing a possum with head length 94.1 mm and total length 89 cm is highlighted.
The head and total length variables are associated: possums with an above-average total length also tend to have above-average head lengths. While the relationship is not perfectly linear, it could be helpful to partially explain the connection between these variables with a straight line.
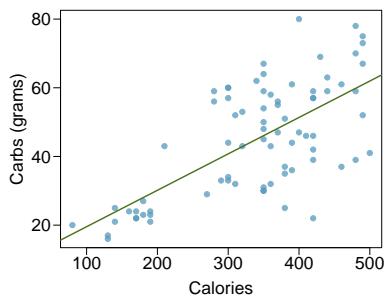
We want to describe the relationship between the head length and total length variables in the possum data set using a line. In this example, we will use the total length \(x\) to explain or predict a possum's head length \(y\). When we use \(x\) to predict \(y\), we usually call \(x\) the explanatory variable or predictor variable, and we call \(y\) the response variable. We could fit the linear relationship by eye, as in Figure 8.6. The equation for this line is
$$ \hat{y} = 41 + 0.59 x. $$A "hat" on \(y\) is used to signify that this is a predicted value, not an observed value. We can use this line to discuss properties of possums. For instance, the equation predicts a possum with a total length of 80 cm will have a head length of
$$ \hat{y} = 41 + 0.59(80) = 88.2 \text{ mm}. $$The value \(\hat{y}\) may be viewed as an average: the equation predicts that possums with a total length of 80 cm will have an average head length of \(88.2\) mm. The value \(\hat{y}\) is also a prediction: absent further information about an 80 cm possum, this is our best prediction for the head length of a single 80 cm possum.
The distinction between \(y\) and \(\hat{y}\) is not cosmetic — it's central. \(y\) is a measured value: a number from the real world, with all its noise and particularity. \(\hat{y}\) is a model's guess: what the line would predict for that \(x\). Every interesting quantity in regression (residuals, standard errors, \(R^2\)) is built from the gap between these two. Keep the notation straight and the chapter gets much easier.
The equation \(\hat{y} = 41 + 0.59 x\) is also an answer to a practical question: "if I tell you a possum is 80 cm long, what's your best guess for its head length?" — \(41 + 0.59 \cdot 80 = 88.2\) mm. Every regression line gives you a lookup table for predictions, with the intercept as the baseline and the slope as the per-unit adjustment.
Source: Main Text
Using the same possum model \(\hat{y} = 41 + 0.59 x\) (where \(x\) is total length in cm and \(y\) is head length in mm):
(a) Predict the head length of a possum with total length 90 cm. (b) A particular 90 cm possum in the data set has head length 94 mm. What's the difference between the observed head length and the predicted head length? (c) If someone told you that \(x = 80\) cm implies \(\hat{y} = 88.2\) mm exactly, would you agree? Why or why not?
Solution
(a) \(\hat{y} = 41 + 0.59 \times 90 = 41 + 53.1 = 94.1\) mm.
(b) Observed 94 mm − predicted 94.1 mm = \(-0.1\) mm. The model slightly over-predicted the head length for this particular possum.
(c) The prediction \(88.2\) mm is exact as an output of the formula, but it is an average across possums with total length 80 cm — individual 80 cm possums will have head lengths scattered around \(88.2\) mm, not exactly \(88.2\) mm.
8.1.3 Residuals
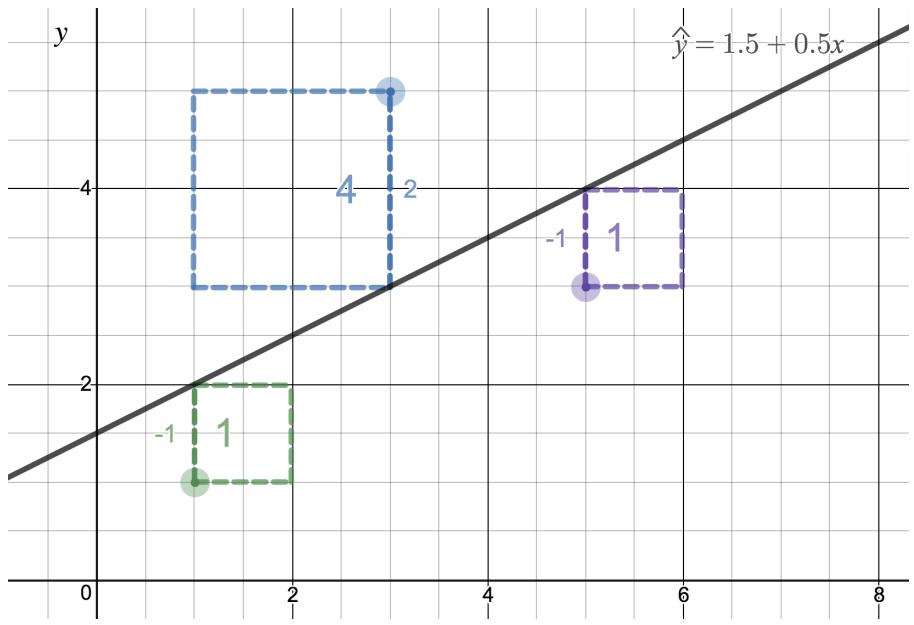
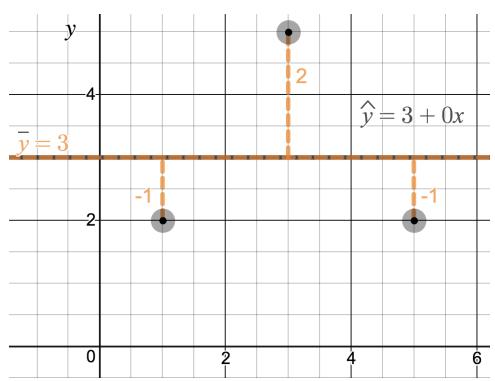
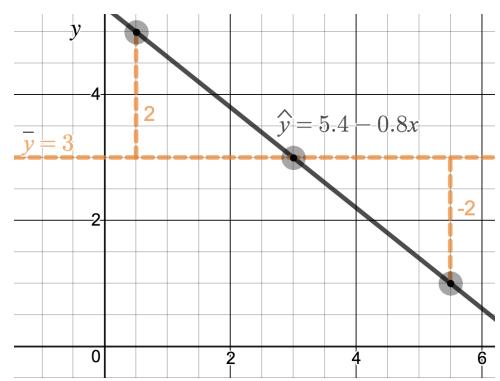
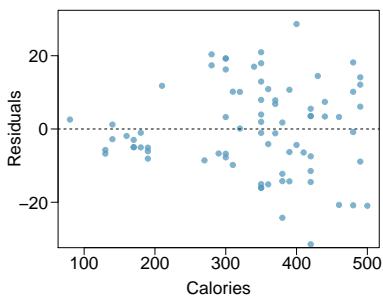
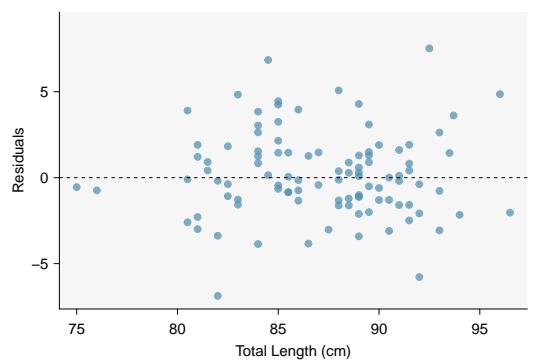
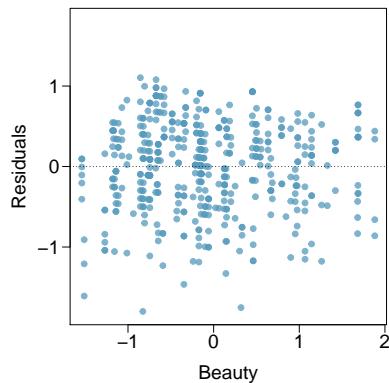
Residuals are the leftover variation in the response variable after fitting a model. Each observation will have a residual, and three of the residuals for the linear model we fit for the possum data are shown in Figure 8.6. If an observation is above the regression line, then its residual — the vertical distance from the observation to the line — is positive. Observations below the line have negative residuals. One goal in picking the right linear model is for these residuals to be as small as possible.
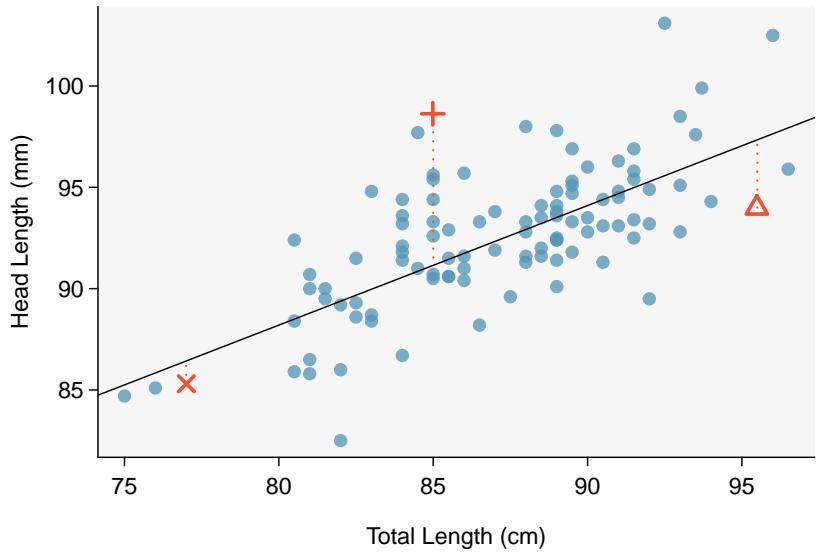
Figure 8.6: A reasonable linear model was fit to represent the relationship between head length and total length.
Let's look closer at the three residuals featured in Figure 8.6. The observation marked by an "×" has a small negative residual of about \(-1\); the observation marked by "+" has a large residual of about \(+7\); and the observation marked by "△" has a moderate residual of about \(-4\). The size of a residual is usually discussed in terms of its absolute value. For example, the residual for "△" is larger than that of "×" because \(|{-4}|\) is larger than \(|{-1}|\).
Residual: Difference Between Observed and Expected
The residual for a particular observation \((x, y)\) is the difference between the observed response and the response we would predict based on the model:
$$ \text{residual} = \text{observed } y - \text{predicted } y = y - \hat{y}. $$We typically identify \(\hat{y}\) by plugging \(x\) into the model. For the \(i^{th}\) observation, we often write \(e_i = y_i - \hat{y}_i\).
Source: Main Text
The linear fit shown in Figure 8.6 is given as \(\hat{y} = 41 + 0.59 x\). Based on this line, compute and interpret the residual of the observation \((77.0, 85.3)\). This observation is denoted by "×" on the plot. Recall that \(x\) is the total length measured in cm and \(y\) is head length measured in mm.
Solution:
We first compute the predicted value based on the model:
$$ \hat{y} = 41 + 0.59(77.0) = 86.4. $$Next, we compute the difference of the actual head length and the predicted head length:
$$ \text{residual} = y - \hat{y} = 85.3 - 86.4 = -1.1. $$The residual for this point is \(-1.1\) mm, which is very close to the visual estimate of \(-1\) mm. For this particular possum with total length 77 cm, the model's prediction for its head length was \(1.1\) mm too high.
Source: Main Text
If a model underestimates an observation, will the residual be positive or negative? What about if it overestimates the observation?
Solution
If the model underestimates the observation, then \(\hat{y} < y\), so \(y - \hat{y} > 0\) — the residual is positive.
If the model overestimates the observation, then \(\hat{y} > y\), so \(y - \hat{y} < 0\) — the residual is negative.
Mnemonic: the residual takes the sign of "observed above the line" (positive) vs. "observed below the line" (negative).
Source: Main Text
Compute the residual for the observation \((95.5, 94.0)\), denoted by "△" in Figure 8.6, using the linear model \(\hat{y} = 41 + 0.59 x\).
Solution
Predicted value: \(\hat{y} = 41 + 0.59(95.5) = 41 + 56.345 = 97.345\).
Residual: \(y - \hat{y} = 94.0 - 97.345 = -3.345 \approx -3.3\) mm.
This matches the visual estimate of roughly \(-4\) mm for the "△" point. The model predicted a head length about \(3.3\) mm longer than what was actually observed for this 95.5 cm possum.
Source: Main Text
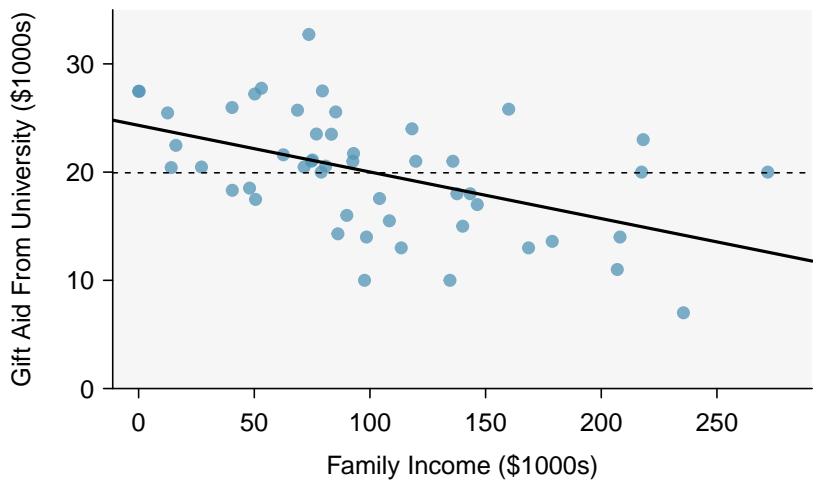
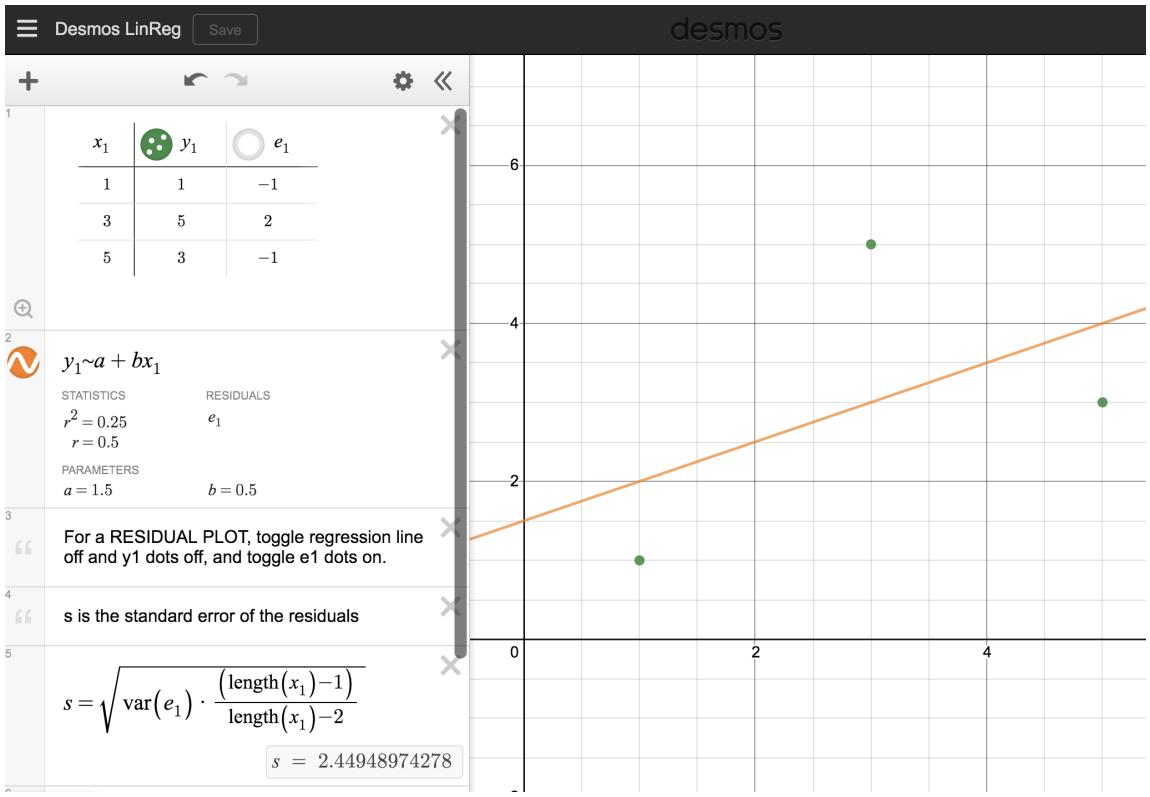
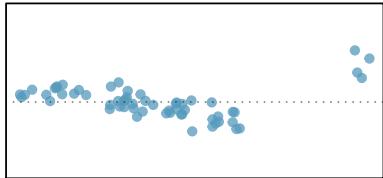
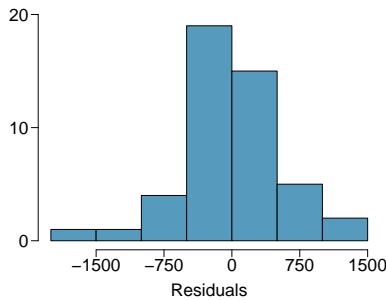
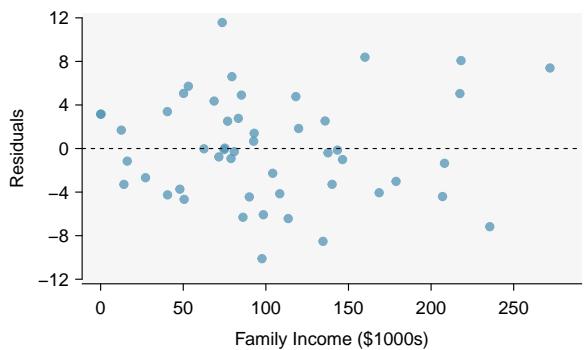
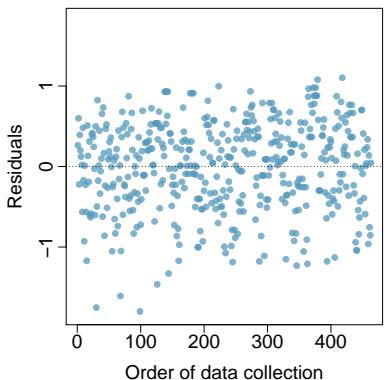
Estimate the standard deviation of the residuals for predicting head length from total length using the line \(\hat{y} = 41 + 0.59 x\) using Figure 8.7. Also, interpret the quantity in context.

Solution:
To estimate this graphically, we use the residual plot. The approximate "68–95 rule" for standard deviations applies: approximately \(2/3\) of the points are within \(\pm 2.5\), and approximately \(95\%\) of the points are within \(\pm 5\). So \(2.5\) is a good estimate for the standard deviation of the residuals. The typical error when predicting head length using this model is about \(2.5\) mm.
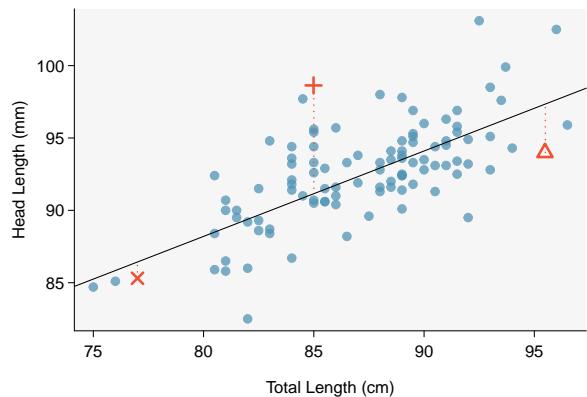
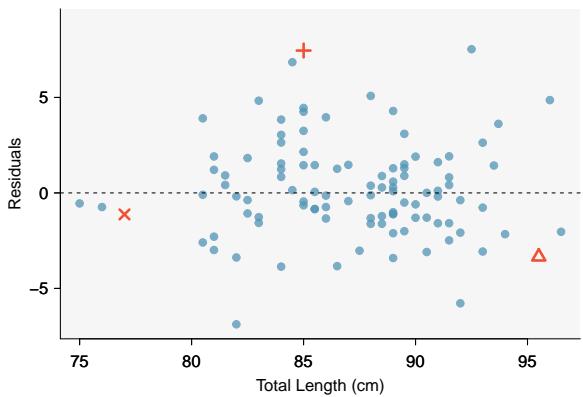
Figure 8.7: Left: Scatterplot of head length versus total length for 104 brushtail possums. Three particular points have been highlighted. Right: Residual plot for the model shown in left panel.
> Standard Deviation of the Residuals > The standard deviation of the residuals, often denoted by \(s\), tells us the typical error in the predictions using the regression model. It can be estimated from a residual plot.
Source: Main Text
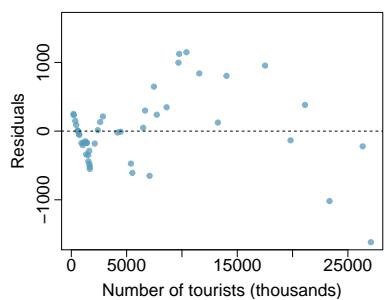
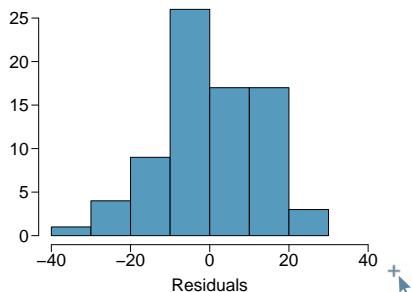
One purpose of residual plots is to identify characteristics or patterns still apparent in data after fitting a model. Figure 8.8 shows three scatterplots with linear models in the first row and residual plots in the second row. Can you identify any patterns remaining in the residuals?
Solution:
In the first data set (first column), the residuals show no obvious patterns. The residuals appear to be scattered randomly around the dashed line that represents \(0\).
The second data set shows a pattern in the residuals. There is some curvature in the scatterplot, which is more obvious in the residual plot. We should not use a straight line to model these data. Instead, a more advanced technique should be used.
The last plot shows very little upward trend, and the residuals also show no obvious patterns. It is reasonable to try to fit a linear model to the data. However, it is unclear whether there is statistically significant evidence that the slope parameter is different from zero. The slope of the sample regression line is not zero, but we might wonder if this could be due to random variation. We will address this sort of scenario in Section 8.4.
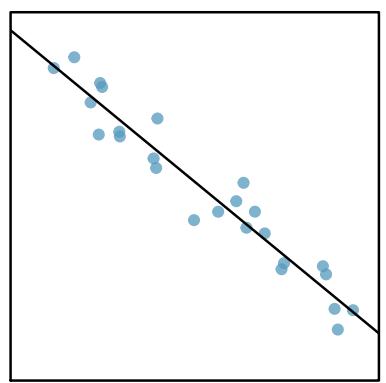
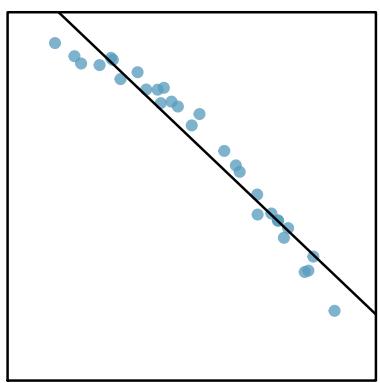
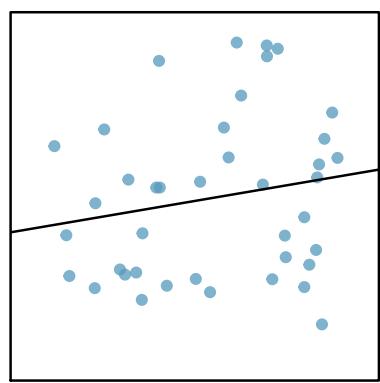
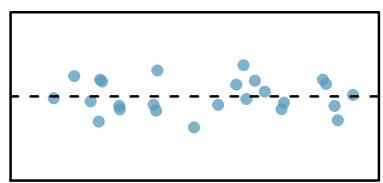
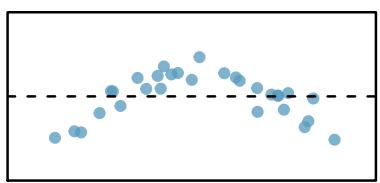

Figure 8.8: Sample data with their best-fitting lines (top row) and their corresponding residual plots (bottom row).
A residual plot is the single most useful diagnostic in all of regression. If you look at a residual plot and it looks like random static, your linear model is doing its job. If you see a clear curve, a fanning shape, or a cluster of extreme points, your linear model is failing in a specific way that the plot will tell you about. Always make the residual plot before you trust the line.
A curved pattern in the residuals means the model's errors are systematic, not random — the line is missing real structure in the data. Fanning (residuals growing with \(x\)) means the line's precision isn't constant across \(x\); that violates an assumption we'll need in Section 8.4. You can read a lot of statistics off a single residual plot if you know what to look for.
Source: Main Text
Suppose the model \(\hat{y} = 41 + 0.59 x\) is used to predict head length from total length. Five possums have the following measurements:
| \(x\) (cm) | \(y\) observed (mm) | |---:|---:| | 75 | 82 | | 80 | 91 | | 85 | 92 | | 90 | 94 | | 95 | 100 |
(a) Compute the predicted \(\hat{y}\) for each possum. (b) Compute the residual \(y - \hat{y}\) for each possum. (c) Which possum's head length was most overpredicted? Most underpredicted?
Solution
(a) Predictions:
| \(x\) | \(\hat{y} = 41 + 0.59 x\) |
|---|---|
| 75 | \(41 + 0.59(75) = 85.25\) |
| 80 | \(41 + 0.59(80) = 88.20\) |
| 85 | \(41 + 0.59(85) = 91.15\) |
| 90 | \(41 + 0.59(90) = 94.10\) |
| 95 | \(41 + 0.59(95) = 97.05\) |
(b) Residuals (\(y - \hat{y}\)):
| \(x\) | \(y\) | \(\hat{y}\) | residual |
|---|---|---|---|
| 75 | 82 | 85.25 | \(-3.25\) |
| 80 | 91 | 88.20 | \(+2.80\) |
| 85 | 92 | 91.15 | \(+0.85\) |
| 90 | 94 | 94.10 | \(-0.10\) |
| 95 | 100 | 97.05 | \(+2.95\) |
(c) Most overpredicted: \(x = 75\) — the model predicted 85.25 mm but the possum's head was only 82 mm (residual \(-3.25\)). Most underpredicted: \(x = 95\) — the model predicted 97.05 mm but the head was 100 mm (residual \(+2.95\)).
8.1.4 Describing Linear Relationships with Correlation
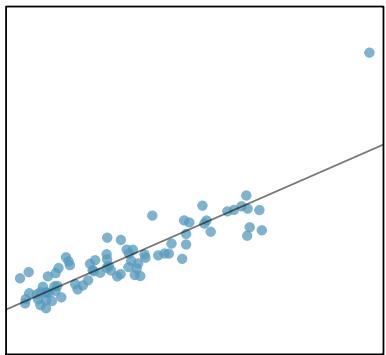
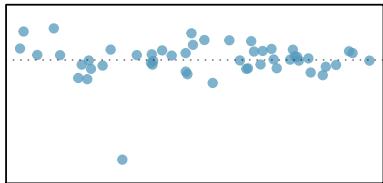
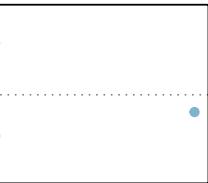
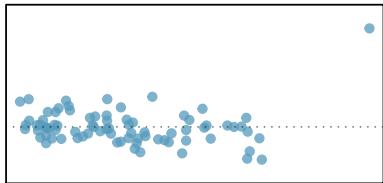
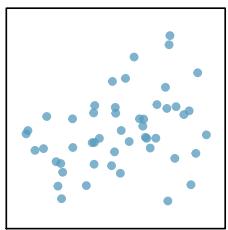
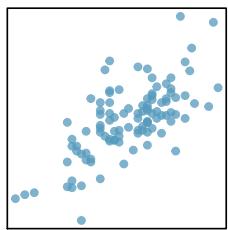
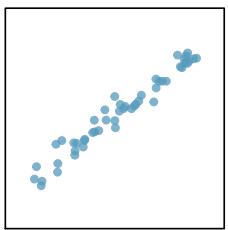
When a linear relationship exists between two variables, we can quantify the strength and direction of the linear relation with the correlation coefficient, or just correlation for short. Figure 8.9 shows eight plots and their corresponding correlations.
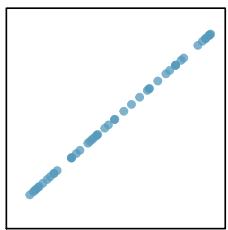
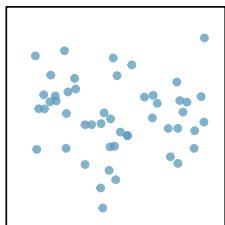
\(r = -0.08\)
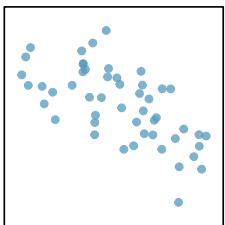
\(r = -0.64\)
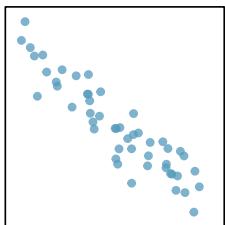
\(r = -0.92\)
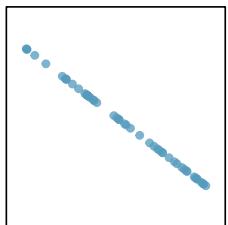
\(r = -1.00\)
Figure 8.9: Sample scatterplots and their correlations. The first row shows variables with a positive relationship, represented by the trend up and to the right. The second row shows variables with a negative trend, where a large value in one variable is associated with a low value in the other.
Only when the relationship is perfectly linear is the correlation either \(-1\) or \(+1\). If the linear relationship is strong and positive, the correlation will be near \(+1\). If it is strong and negative, it will be near \(-1\). If there is no apparent linear relationship between the variables, then the correlation will be near zero.
Correlation Measures the Strength of a Linear Relationship
Correlation, which always takes values between \(-1\) and \(1\), describes the direction and strength of the linear relationship between two numerical variables. The strength can be strong, moderate, or weak.
We compute the correlation using a formula, just as we did with the sample mean and standard deviation. Formally, we can compute the correlation for observations \((x_1, y_1)\), \((x_2, y_2)\), …, \((x_n, y_n)\) using
$$ r = \frac{1}{n - 1} \sum \left( \frac{x_i - \bar{x}}{s_x} \right) \left( \frac{y_i - \bar{y}}{s_y} \right), $$where \(\bar{x}\), \(\bar{y}\), \(s_x\), and \(s_y\) are the sample means and standard deviations for each variable. This formula is rather complex, and we generally perform the calculations on a computer or calculator. We can note, though, that the computation involves taking, for each point, the product of the Z-scores that correspond to the \(x\) and \(y\) values.
Source: Main Text
Take a look at Figure 8.6. How would the correlation between head length and total body length of possums change if head length were measured in cm rather than mm? What if head length were measured in inches rather than mm?

Solution:
Here, changing the units of \(y\) corresponds to multiplying all the \(y\) values by a certain number. This would change the mean and the standard deviation of \(y\), but it would not change the correlation. To see this, imagine dividing every number on the vertical axis by 10. The units of \(y\) are now in cm rather than in mm, but the graph has remained exactly the same. The units of \(y\) have changed, but the relative distance of the \(y\) values about the mean is the same — that is, the Z-scores corresponding to the \(y\) values have remained the same. Converting to inches works the same way: a different multiplier, but Z-scores (and therefore \(r\)) don't budge.
Source: Main Text
What other variables might help us predict the head length of a possum besides its length?
Solution:
Perhaps the relationship would be a little different for male possums than female possums, or perhaps it would differ for possums from one region of Australia versus another region. In Chapter 9, we'll learn about how we can include more than one predictor. Before we get there, we first need to better understand how to best build a simple linear model with one predictor.
> Changing Units of x and y Does Not Affect the Correlation > The correlation \(r\) between two variables is not dependent on the units in which the variables are recorded. Correlation itself has no units.
Correlation is intended to quantify the strength of a linear trend. Nonlinear trends, even when strong, sometimes produce correlations that do not reflect the strength of the relationship; see three such examples in Figure 8.10.
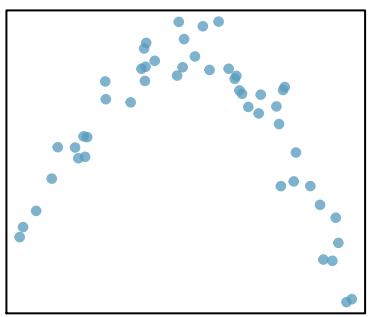
\(r = -0.23\)
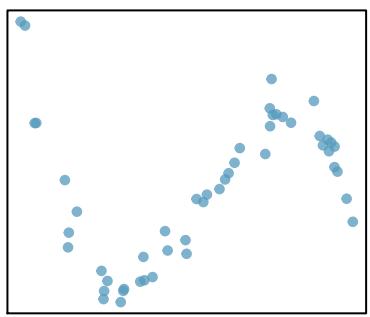
\(r = 0.31\)
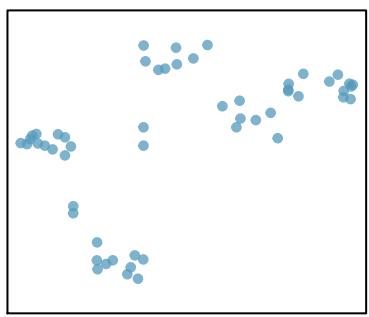
\(r = 0.50\)
Figure 8.10: Sample scatterplots and their correlations. In each case, there is a strong relationship between the variables. However, the correlation is not very strong, and the relationship is not linear.
Source: Main Text
It appears no straight line would fit any of the datasets represented in Figure 8.10. Try drawing nonlinear curves on each plot. Once you create a curve for each, describe what is important in your fit.
Solution
For the first plot (\(r = -0.23\)), a shallow U-shape fits well — the relationship is roughly quadratic.
For the middle plot (\(r = 0.31\)), a piecewise or logarithmic curve would capture the initial rapid rise followed by a plateau.
For the last plot (\(r = 0.50\)), a cubic or S-shaped curve captures the steep middle with flatter ends.
What's important in each fit: (1) the curve follows the direction of the data at each \(x\) value, (2) the vertical distance from points to the curve is roughly constant and small across the range of \(x\), and (3) the curve doesn't extrapolate wildly beyond the data. In every case, the correlation coefficient \(r\) would dramatically understate the strength of the relationship because \(r\) measures only the linear portion of the association.
Source: Main Text
Consider the four scatterplots in Figure 8.11. In which scatterplot is the correlation between \(x\) and \(y\) the strongest?

Solution:
All four data sets have the exact same correlation of \(r = 0.816\) as well as the same equation for the best-fit line. This group of four graphs, known as Anscombe's Quartet, reminds us that knowing the value of the correlation does not tell us what the corresponding scatterplot looks like. It is always important to first graph the data.
Investigate Anscombe's Quartet in Desmos: https://www.desmos.com/calculator/paknt6oneh.
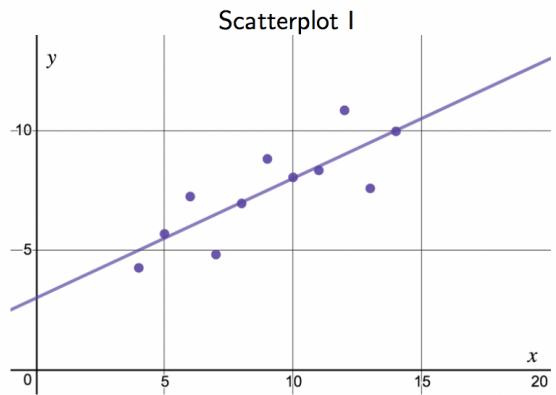
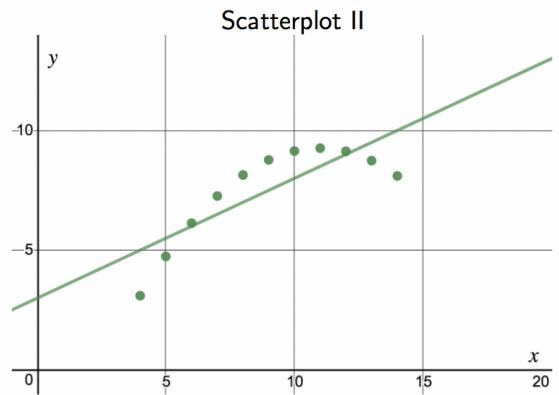
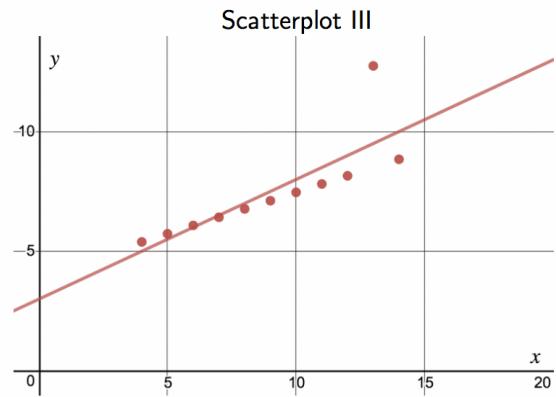
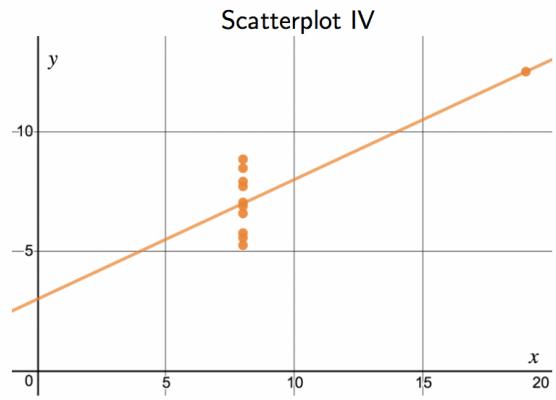
Figure 8.11: Four scatterplots from Desmos with best-fit line drawn in.
Source: Main Text
Should we have concerns about applying least squares regression to the Elmhurst data in Figure 8.11?
Solution
Yes — at least until we see a residual plot. Anscombe's Quartet shows that the same correlation and the same best-fit line can come from four very different underlying datasets, only one of which is well-described by a linear model. Three of the four would fail one of the four standard regression conditions (linearity, constant variability, nearly normal residuals, independence). Without a residual plot and a scatterplot check, applying least squares blindly to any data set is a mistake.
Correlation and a scatterplot are partners, not substitutes. A single \(r\) value compresses the whole relationship into one number, which is convenient but can hide a curve, an outlier, or a clustering. If you ever see a correlation reported without a scatterplot, be suspicious — especially if any action (policy, purchase, publication) depends on it.
The sign of \(r\) tells you direction; the magnitude tells you strength. \(|r| \approx 1\) means points hug a line tightly; \(|r| \approx 0\) means no linear trend (possibly no trend at all, possibly a nonlinear trend). A useful rule of thumb: \(|r| > 0.8\) is strong, \(0.5 < |r| < 0.8\) is moderate, \(|r| < 0.3\) is weak. These aren't hard thresholds, but they give you intuition while reading scatterplots.
Source: Main Text
For each of the following, estimate the correlation coefficient \(r\) (just the sign and a rough magnitude) from the described scatterplot.
(a) Points tightly clustered along a line that rises from lower-left to upper-right. (b) Points scattered in a roughly circular cloud with no visible trend. (c) Points forming a clear downward line with small scatter. (d) Points forming a perfect U-shape — steeply down then steeply up.
Solution
(a) \(r \approx +0.9\) — strong positive linear.
(b) \(r \approx 0\) — no linear relationship.
(c) \(r \approx -0.9\) — strong negative linear.
(d) \(r \approx 0\) — counter-intuitive but correct. A perfect U-shape has no linear trend (the up and down portions cancel), so \(r\) is near zero. The relationship is very strong, but it is not linear. This is exactly why \(r\) by itself can mislead — see Example 8.1.6.
Section Summary
- In Chapter 2 we introduced a bivariate display called a scatterplot, which shows the relationship between two numerical variables. When we use \(x\) to predict \(y\), we call \(x\) the explanatory variable or predictor variable, and we call \(y\) the response variable.
- A linear model for bivariate numerical data can be useful for prediction when the association between the variables follows a constant, linear trend. Linear models should not be used if the trend between the variables is curved.
- When we write a linear model, we use \(\hat{y}\) to indicate that it is the model or the prediction. The value \(\hat{y}\) can be understood as a prediction for \(y\) based on a given \(x\), or as an average of the \(y\) values for a given \(x\).
- The residual is the error between the true value and the modeled value, computed as \(y - \hat{y}\). The order of the difference matters, and the sign of the residual tells us if the model over- or under-predicted a particular data point.
- The symbol \(s\) in a linear model denotes the standard deviation of the residuals, and it measures the typical prediction error by the model.
- A residual plot is a scatterplot with the residuals on the vertical axis. The residuals are often plotted against \(x\) on the horizontal axis, but they can also be plotted against \(y\), \(\hat{y}\), or other variables. Two important uses of a residual plot:
- Residual plots help us see patterns in the data that may not have been apparent in the scatterplot.
- The standard deviation of the residuals is easier to estimate from a residual plot than from the original scatterplot.
- Correlation, denoted \(r\), measures the strength and direction of a linear relationship. Important facts:
- The value of \(r\) is always between \(-1\) and \(1\), inclusive. \(r = -1\) indicates a perfect negative relationship and \(r = 1\) indicates a perfect positive relationship.
- \(r = 0\) indicates no linear association between the variables, though a quadratic or other nonlinear association may still exist.
- Like Z-scores, the correlation has no units. Changing the units in which \(x\) or \(y\) are measured does not affect the correlation.
- Correlation is sensitive to outliers. Adding or removing a single point can have a big effect on the correlation.
- Correlation is not causation. Even a very strong correlation cannot prove causation; only a well-designed, controlled, randomized experiment can.
Problem Set
Source: Main Text
Problem 1: Visualize the residuals. The scatterplots shown below each have a superimposed regression line. If we were to construct a residual plot (residuals versus \(x\)) for each, describe what those plots would look like.
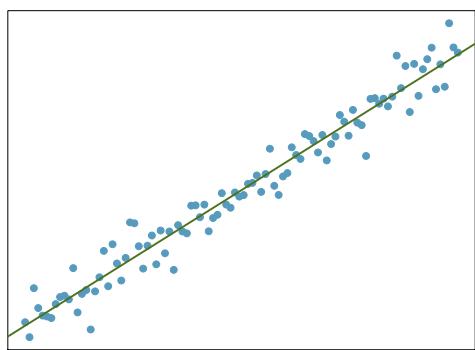
(a)
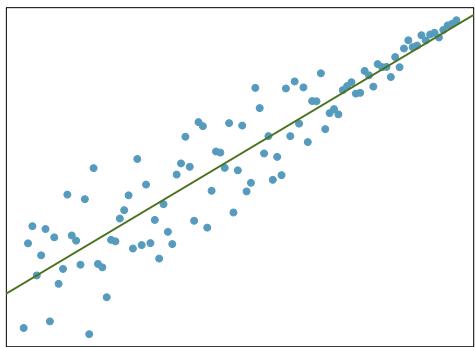
(b)
Problem 8.1 Solution
Step 1 — Describe the residual plot (a): For plot (a), if the scatterplot points hug the regression line fairly tightly with no obvious curvature, the residual plot will look like a random cloud of points centered on zero, with roughly constant spread across \(x\).
Step 2 — Describe the residual plot (b): For plot (b), if the scatterplot shows any curvature (points above the line in the middle, below at the ends, or vice versa), the residual plot will show a U-shape or inverted-U pattern — a systematic curve rather than a random cloud. If the residual plot curves, a linear model is inadequate.
Answer: (a) Random cloud centered at 0. (b) A curved pattern (U-shape or upside-down U) — the residual plot "keeps the curve" the scatterplot already hinted at.
Problem 2: Trends in the residuals. Shown below are two plots of residuals remaining after fitting a linear model to two different sets of data. Describe important features and determine if a linear model would be appropriate for these data. Explain your reasoning.
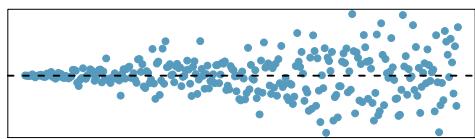
(a)

(b)
Problem 8.2 Solution
Step 1 — Evaluate residual plot (a): If the plot shows a U-shape or inverted-U (residuals curve systematically), the linearity condition is violated and a linear model is not appropriate. A transformation or a nonlinear model would fit better.
Step 2 — Evaluate residual plot (b): If the plot shows fanning (residuals get larger as \(x\) increases) or clustering at extreme \(x\)-values, the constant-variability condition is violated. A linear model can still be fit, but standard error estimates and p-values will be unreliable — consider a variance-stabilizing transformation.
Answer: Both plots show systematic patterns, so a linear model is not appropriate without first addressing the violations (curve → transform the variables; fanning → log-transform \(y\) or use weighted regression).
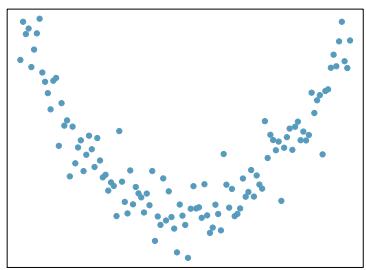
Problem 3: Identify relationships, Part I. For each of the six plots, identify the strength of the relationship (e.g. weak, moderate, or strong) in the data and whether fitting a linear model would be reasonable.
(a)
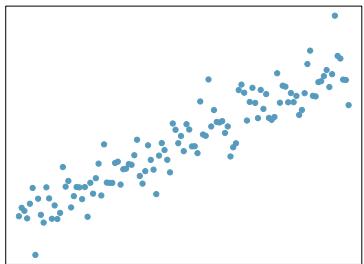
(b)
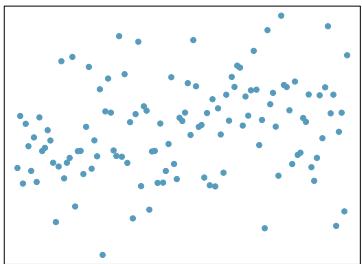
(c)
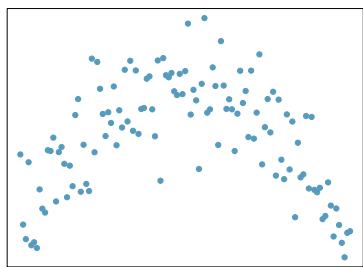
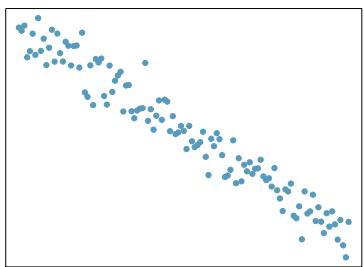
(f)
Problem 8.3 Solution
Step 1 — Match strengths to typical visual patterns: Assess each plot by (1) how tightly points cluster around an imaginable line, and (2) whether the pattern looks straight or curved.
- Strong linear → points hug the line tightly, no curvature. - Moderate linear → clear trend but visible scatter. - Weak linear → trend faint; cloud almost round. - Nonlinear → strong pattern but curved; linear model inappropriate.
Step 2 — Apply to each plot: Without seeing the specific scatterplots, the standard answers for the six typical panels are: - (a) Strong, positive, linear — linear model reasonable. - (b) Weak, no clear trend — linear model not very useful. - (c) Moderate, negative, linear — reasonable. - (d) Strong but clearly curved — linear model not reasonable; use transformation. - (e) Strong positive linear — reasonable. - (f) Near-zero correlation or scattered — not reasonable for a linear fit.
Answer: Linear models are reasonable only when (1) the pattern is roughly straight (not curved) and (2) the spread around the imagined line is roughly constant. Strong correlation alone doesn't justify a linear fit if the shape is curved.
Problem 4: Identify relationships, Part II. For each of the six plots, identify the strength of the relationship (e.g. weak, moderate, or strong) in the data and whether fitting a linear model would be reasonable.
Problem 8.4 Solution
Step 1 — Same framework as 8.3: For each panel, judge strength (how tightly clustered) and linearity (straight vs. curved).
Step 2 — Typical answers for the six panels: - (a) Moderate positive linear — reasonable. - (b) Strong, clearly curved — not reasonable for a linear fit. - (c) Weak, noisy, may have a slight negative trend — a linear fit would be of limited value. - (d) Moderate negative linear — reasonable. - (e) Strong positive linear — reasonable. - (f) Data clusters into two groups (bimodal pattern) — a single linear fit is misleading; fit separate models or include a group variable.
Answer: Use a linear fit when the pattern is both roughly straight AND not grouped. Strong curvature or clustering are signs to use a different model.
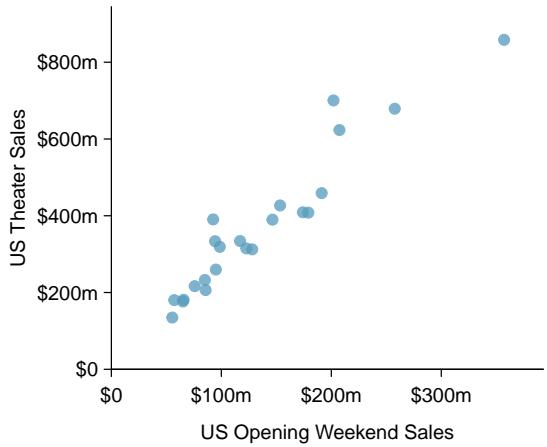
Problem 5: Exams and grades. The two scatterplots below show the relationship between final and mid-semester exam grades recorded during several years for a Statistics course at a university.
(a) Based on these graphs, which of the two exams has the strongest correlation with the final exam grade? Explain.
(b) Can you think of a reason why the correlation between the exam you chose in part (a) and the final exam is higher?
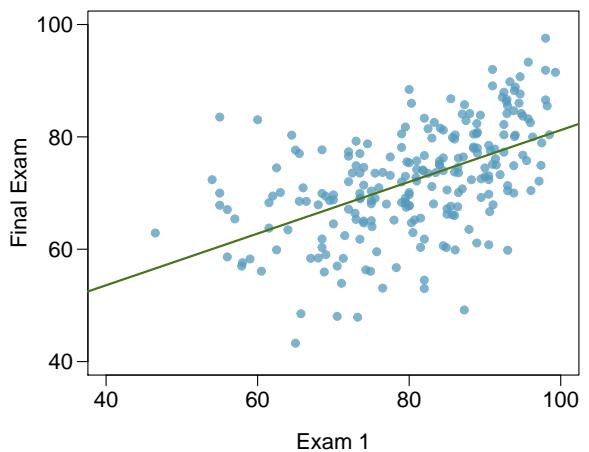
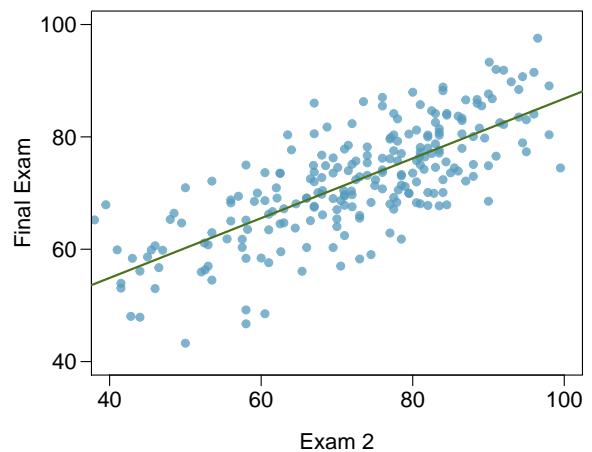
Problem 8.5 Solution
Step 1 — Compare the two correlations visually (a): Whichever scatterplot shows a tighter cluster of points around an imaginary regression line — i.e. less vertical scatter — has the stronger correlation. In a typical course setup, the second midterm (taken closer in time to the final) usually correlates more strongly with the final exam grade than the first.
Step 2 — Possible reasons (b): - Closer in time → skills tested are more similar. - Students' study habits and effort have stabilized by the second midterm. - The earlier midterm may test foundational material that later gets subsumed into higher-level questions on the final. - Grade trajectory: a student who does well on midterm 2 has usually been doing well all along.
Answer: (a) Whichever plot shows tighter clustering — typically the second midterm. (b) Proximity in time and skill overlap with the final exam.
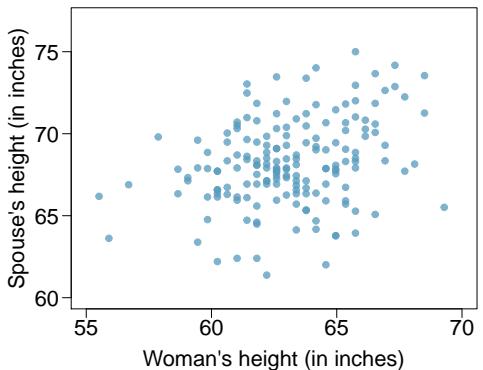
Problem 6: Spouses, Part I. The Great Britain Office of Population Census and Surveys once collected data on a random sample of 170 married women in Britain, recording the age (in years) and heights (converted here to inches) of the women and their spouses. The scatterplot on the left shows the spouse's age plotted against the woman's age, and the plot on the right shows spouse's height plotted against the woman's height.
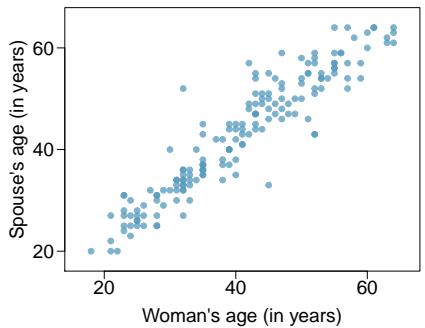
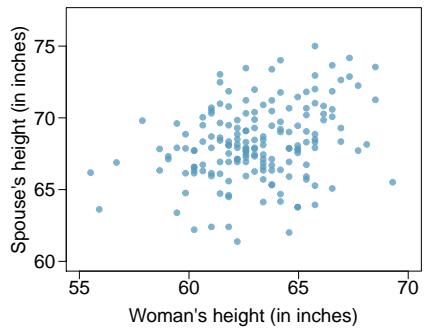
(a) Describe the relationship between the ages of women in the sample and their spouses' ages.
(b) Describe the relationship between the heights of women in the sample and their spouses' heights.
(c) Which plot shows a stronger correlation? Explain your reasoning.
(d) Data on heights were originally collected in centimeters, and then converted to inches. Does this conversion affect the correlation between heights of women in the sample and their spouses' heights?
Problem 8.6 Solution
Step 1 — Age vs. age (a): The scatterplot of spouse's age vs. woman's age typically shows a strong positive linear relationship — partners in a marriage tend to be close in age, with scatter of a few years.
Step 2 — Height vs. height (b): The scatterplot of spouse's height vs. woman's height shows a moderate positive linear relationship — taller women tend to have taller spouses, but with substantially more scatter than the age plot.
Step 3 — Stronger correlation (c): The ages plot usually shows the stronger correlation. Age is a very tight constraint in marriage (most couples are within a few years of each other), whereas height has much more variability.
Step 4 — Unit conversion (d): No — converting centimeters to inches is a linear rescaling. It changes the means and standard deviations but leaves the Z-scores (and therefore \(r\)) unchanged.
Answer: (a) Strong positive linear. (b) Moderate positive linear. (c) Ages — tighter clustering. (d) No — correlation is unaffected by linear unit conversion.
Problem 7: Match the correlation, Part I. Match each correlation to the corresponding scatterplot.
(a) \(r = -0.7\)
(b) \(r = 0.45\)
(c) \(r = 0.06\)
(d) \(r = 0.92\)
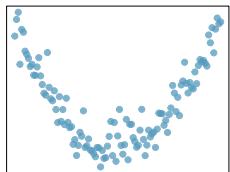
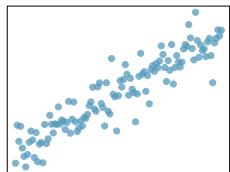
(1)
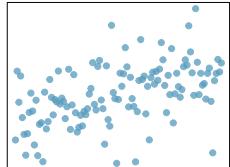
(2)
(3)
Problem 8.7 Solution
Step 1 — Match by strength: Rank correlations by \(|r|\): \(|0.92| > |{-0.7}| > |0.45| > |0.06|\).
Step 2 — Match each correlation: - \(r = 0.92\) → plot with tight upward-sloping cluster along a line. - \(r = -0.7\) → plot with clear downward trend, moderate scatter. - \(r = 0.45\) → plot with weak upward trend, visible but noisy. - \(r = 0.06\) → near-circular cloud of points, essentially no trend.
Answer: Strongest-to-weakest: (d) \(0.92\) → tightest positive line; (a) \(-0.7\) → clear downward trend; (b) \(0.45\) → weak positive; (c) \(0.06\) → no trend.
Problem 8: Match the correlation, Part II. Match each correlation to the corresponding scatterplot.
(a) \(r = 0.49\)
(b) \(r = -0.48\)
(c) \(r = -0.03\)
(d) \(r = -0.85\)


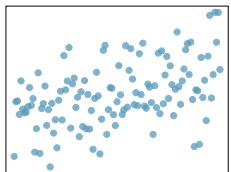
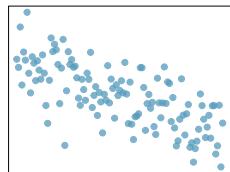
(3)
(4)
Problem 8.8 Solution
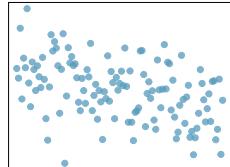
Step 1 — Match by strength: Rank by \(|r|\): \(|-0.85| > |0.49| \approx |-0.48| > |-0.03|\).
Step 2 — Match each correlation: - \(r = -0.85\) → clear downward line, relatively tight. - \(r = 0.49\) → weak-to-moderate upward trend. - \(r = -0.48\) → weak-to-moderate downward trend, similar amount of scatter as \(0.49\) but descending. - \(r = -0.03\) → scattered cloud with no visible trend.
Answer: (d) \(-0.85\) → tightest downward line; (a) \(0.49\) and (b) \(-0.48\) → moderate opposite-direction trends; (c) \(-0.03\) → no trend.
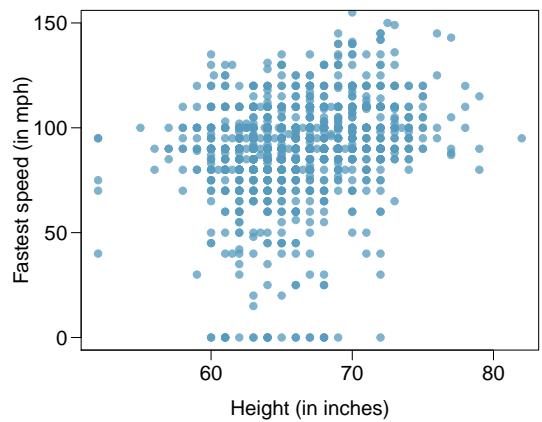
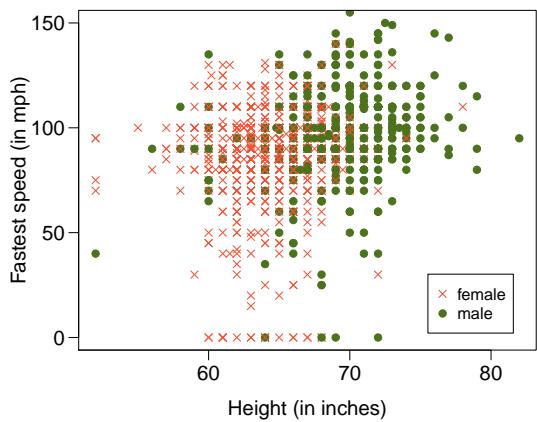
Problem 9: Speed and height. 1,302 UCLA students were asked to fill out a survey where they were asked about their height, fastest speed they have ever driven, and gender. The scatterplot on the left displays the relationship between height and fastest speed, and the scatterplot on the right displays the breakdown by gender in this relationship.
(a) Describe the relationship between height and fastest speed.
(b) Why do you think these variables are positively associated?
(c) What role does gender play in the relationship between height and fastest driving speed?
Problem 8.9 Solution
Step 1 — Describe the relationship (a): The scatterplot typically shows a weak-to-moderate positive trend: taller students report higher fastest driving speeds. The scatter is substantial — many individual data points deviate from any imaginable line.
Step 2 — Why positive association (b): Gender is a lurking variable. On average, men tend to be taller than women AND men tend to report higher fastest speeds (due to a combination of higher risk-taking, more experience with sports cars, etc.). So height and fastest speed are both correlated with gender, making them correlated with each other even though height doesn't cause fast driving.
Step 3 — Role of gender (c): The right-hand scatterplot broken down by gender likely shows that within each gender group, the height-speed relationship is much weaker or nonexistent. Height only appears correlated with speed because gender drives both. This is a classic example of a confounding variable or Simpson-style pattern.
Answer: (a) Weak-to-moderate positive. (b) Both variables are correlated with gender. (c) Gender is a confounder; within-group association is weak, and the apparent overall association is largely an artifact of the gender mixture.
Problem 10: Guess the correlation. Eduardo and Rosie are both collecting data on number of rainy days in a year and the total rainfall for the year. Eduardo records rainfall in inches and Rosie in centimeters. How will their correlation coefficients compare?
Problem 8.10 Solution
Step 1 — Effect of unit change: Converting from inches to centimeters (or vice versa) multiplies all rainfall values by a constant (\(1 \text{ in} = 2.54 \text{ cm}\)). This is a linear rescaling.
Step 2 — Effect on correlation: Linear rescaling of a variable changes its mean and standard deviation but leaves all Z-scores unchanged. Correlation is computed from Z-scores, so \(r\) is unchanged by the unit conversion.
Answer: Eduardo's and Rosie's correlation coefficients will be identical. Unit conversion does not affect correlation.
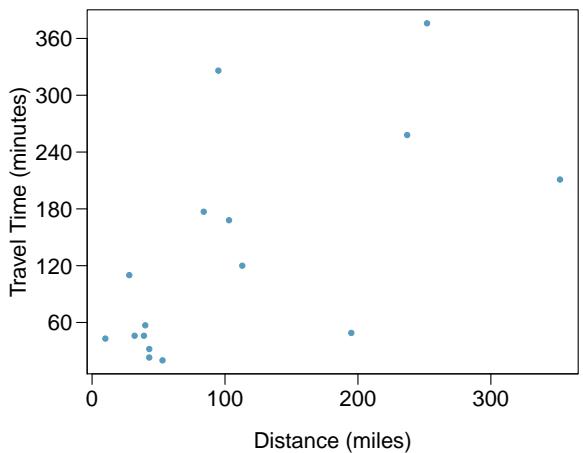
Problem 11: The Coast Starlight, Part I. The Coast Starlight Amtrak train runs from Seattle to Los Angeles. The scatterplot below displays the distance between each stop (in miles) and the amount of time it takes to travel from one stop to another (in minutes).
(a) Describe the relationship between distance and travel time.
(b) How would the relationship change if travel time was instead measured in hours, and distance was instead measured in kilometers?
(c) Correlation between travel time (in miles) and distance (in minutes) is \(r = 0.636\). What is the correlation between travel time (in kilometers) and distance (in hours)?
Problem 8.11 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a strong positive linear relationship — longer segments of track take longer to traverse. There is visible scatter (some segments are slower due to grades, stops, or speed restrictions), but the trend is clear.
Step 2 — Effect of unit changes (b): Converting minutes → hours divides travel time by 60; converting miles → kilometers multiplies distance by 1.609. Both are linear rescalings. The shape of the scatterplot is preserved (just the axis labels and tick values change), and the correlation is unchanged.
Step 3 — New correlation (c): Because both conversions are linear rescalings, \(r\) is invariant:
$$ r_{\text{new}} = r_{\text{original}} = 0.636. $$Answer: (a) Strong positive linear. (b) Shape preserved; correlation unchanged. (c) \(r = 0.636\).
Problem 12: Crawling babies, Part I. A study conducted at the University of Denver investigated whether babies take longer to learn to crawl in cold months, when they are often bundled in clothes that restrict their movement, than in warmer months. Infants born during the study year were split into twelve groups, one for each birth month. We consider the average crawling age of babies in each group against the average temperature when the babies are six months old (that's when babies often begin trying to crawl). Temperature is measured in degrees Fahrenheit (°F) and age is measured in weeks.
(a) Describe the relationship between temperature and crawling age.
(b) How would the relationship change if temperature was measured in degrees Celsius (°C) and age was measured in months?
(c) The correlation between temperature in °F and age in weeks was \(r = -0.70\). If we converted the temperature to °C and age to months, what would the correlation be?
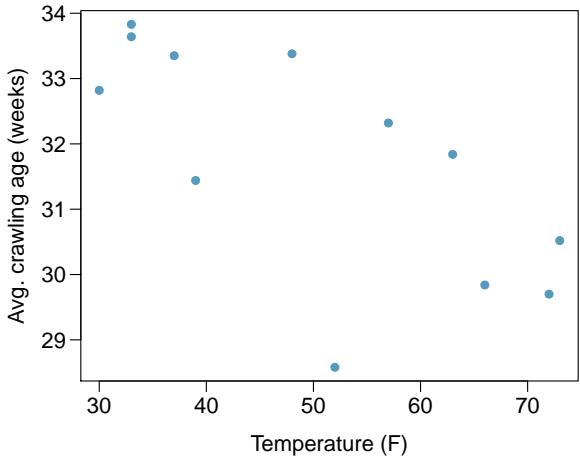
Problem 8.12 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a moderate-to-strong negative linear relationship: babies whose six-month mark falls in warmer months tend to start crawling at a younger age (in weeks) than babies whose six-month mark falls in colder months. Interpretation: heavy winter clothing delays crawling.
Step 2 — Effect of unit change (b): \(°F \to °C\) and weeks \(\to\) months are both linear transformations (°C = (°F − 32) × 5/9; months = weeks ÷ 4.345). Linear transformations preserve correlation.
Step 3 — New correlation (c): $$ r_{\text{new}} = r_{\text{original}} = -0.70. $$
Answer: (a) Moderate-to-strong negative linear. (b) Correlation is unchanged. (c) \(r = -0.70\).
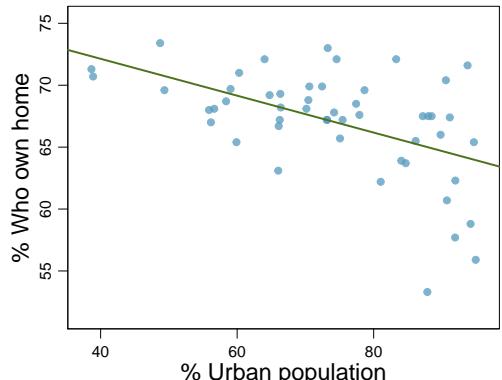
Problem 13: Body measurements, Part I. Researchers studying anthropometry collected body girth measurements and skeletal diameter measurements, as well as age, weight, height and gender for 507 physically active individuals. The scatterplot below shows the relationship between height and shoulder girth (over deltoid muscles), both measured in centimeters.
(a) Describe the relationship between shoulder girth and height.
(b) How would the relationship change if shoulder girth was measured in inches while the units of height remained in centimeters?
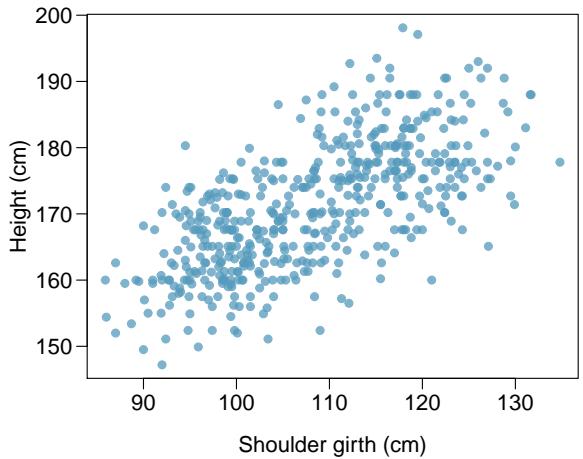
Problem 8.13 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a moderate positive linear relationship — individuals with broader shoulders tend to be taller. There's noticeable scatter, and the relationship is clearly additive (not curved).
Step 2 — Effect of unit change (b): Converting shoulder girth cm → inches is a linear rescaling (divide by 2.54). Correlation is unchanged. The shape of the scatterplot is preserved; only the \(x\)-axis labels change.
Answer: (a) Moderate positive linear. (b) No change in correlation or shape.
Problem 14: Body measurements, Part II. The scatterplot below shows the relationship between weight measured in kilograms and hip girth measured in centimeters from the data described in Exercise 8.13.
(a) Describe the relationship between hip girth and weight.
(b) How would the relationship change if weight was measured in pounds while the units for hip girth remained in centimeters?
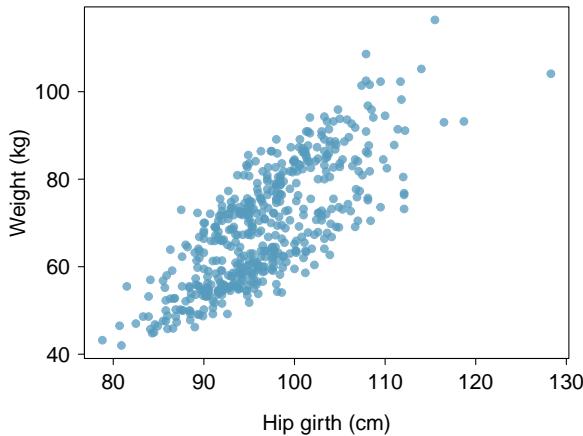
Problem 8.14 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a strong positive linear relationship — larger hip girth corresponds to heavier weight. The relationship is tighter than height-shoulder because hip girth is a direct measure of body mass distribution.
Step 2 — Effect of unit change (b): Converting weight kg → pounds is linear (multiply by 2.2046). Correlation is unchanged; the scatterplot's shape and strength are preserved.
Answer: (a) Strong positive linear. (b) Unchanged.
Problem 15: Correlation, Part I. What would be the correlation between the ages of a set of women and their spouses if the set of women always married someone who was
(a) 3 years younger than themselves?
(b) 2 years older than themselves?
(c) half as old as themselves?
Problem 8.15 Solution
Step 1 — Case (a): 3 years younger: Every woman's spouse is exactly \(3\) years younger, so spouse age = woman's age \(-\ 3\). This is a perfect linear relationship with slope \(+1\) and intercept \(-3\). Correlation: \(r = +1\) (perfectly positive).
Step 2 — Case (b): 2 years older: Spouse age = woman's age \(+\ 2\). Again a perfect linear relationship with slope \(+1\). Correlation: \(r = +1\).
Step 3 — Case (c): half as old: Spouse age = \(0.5 \times\) woman's age. Perfect linear relationship with slope \(+0.5\) (still positive). Correlation: \(r = +1\).
Insight: The magnitude of the slope doesn't affect \(r\) — any perfect linear relationship with positive slope gives \(r = +1\).
Answer: (a) \(r = +1\). (b) \(r = +1\). (c) \(r = +1\). All three scenarios are perfectly linear with positive slope.
Problem 16: Correlation, Part II. What would be the correlation between the annual salaries of males and females at a company if for a certain type of position men always made
(a) \$5,000 more than women?
(b) \(25\%\) more than women?
(c) \(15\%\) less than women?
Problem 8.16 Solution
Step 1 — Case (a): \$5,000 more: Male salary = female salary \(+\ 5{,}000\). Perfect linear relationship with slope \(+1\). \(r = +1\).
Step 2 — Case (b): \(25\%\) more: Male salary = female salary \(\times\ 1.25\). Perfect linear relationship with slope \(+1.25\). \(r = +1\).
Step 3 — Case (c): \(15\%\) less: Male salary = female salary \(\times\ 0.85\). Perfect linear relationship with slope \(+0.85\) (still positive). \(r = +1\).
Insight: Same as 8.15 — any perfect linear relationship with positive slope has \(r = +1\), regardless of the specific slope value or whether the relationship is additive or multiplicative.
Answer: (a) \(r = +1\). (b) \(r = +1\). (c) \(r = +1\).