8.2 Fitting a Line by Least Squares Regression
In this section we answer questions that matter for anyone who uses data to make predictions:
- How well can we predict financial aid based on family income for a particular college?
- How do we find, interpret, and apply the least squares regression line?
- How do we measure the fit of a model and compare different models to each other?
- Why do models sometimes make predictions that are ridiculous — or even impossible?
Fitting a line by eye (like we did in Section 8.1) is a great first instinct, but it is not reproducible — two people will draw two different lines through the same scatterplot, and neither can defend their choice as best. The least squares regression line solves that problem by giving us an objective, formula-driven answer: out of every possible line, it picks the one that makes the squared prediction errors as small as possible. Every computer statistics package, every graphing calculator's LinReg button, and every professional regression study uses this criterion.
Squaring the residuals — instead of just adding up their absolute values — sounds arbitrary, but it has teeth. A residual of 4 is not twice as bad as a residual of 2; it is four times as bad (\(4^2 = 16\) vs. \(2^2 = 4\)) under the squared-error criterion. That heavy penalty on large misses is exactly why least squares produces lines that hug the bulk of the data instead of tolerating a few wild outliers.
Learning Objectives
Source: Main Text
By the end of this section, you should be able to:
- Calculate the slope and \(y\)-intercept of the least squares regression line using the relevant summary statistics. Interpret these quantities in context.
- Understand why the least squares regression line is called the least squares regression line.
- Interpret the explained variance \(R^2\).
- Understand the concept of extrapolation and why it is dangerous.
- Identify outliers and influential points in a scatterplot.
8.2.1 An Objective Measure for Finding the Best Line
Fitting linear models by eye is open to criticism since it depends on an individual's preference. In this section, we use least squares regression as a more rigorous approach.
This section considers family income and gift aid data from a random sample of fifty students in the freshman class of Elmhurst College in Illinois. Gift aid is financial aid that does not need to be paid back, as opposed to a loan. A scatterplot of the data is shown in Figure 8.12 along with two linear fits. The lines follow a negative trend in the data — students who have higher family incomes tended to have lower gift aid from the university.
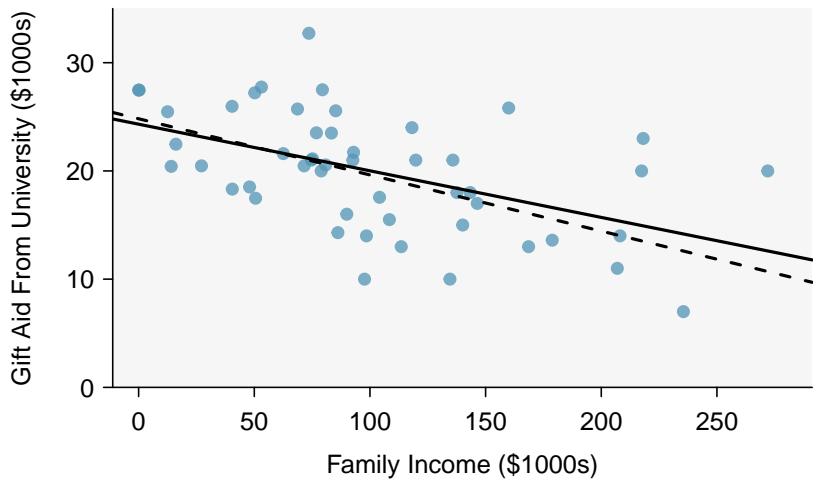
Figure 8.12: Gift aid and family income for a random sample of 50 freshman students from Elmhurst College. Two lines are fit to the data, the solid line being the least squares line.
We begin by thinking about what we mean by best. Mathematically, we want a line that has small residuals. One criterion could be to minimize the sum of the residual magnitudes:
$$ \left| y_{1} - \hat{y}_{1} \right| + \left| y_{2} - \hat{y}_{2} \right| + \dots + \left| y_{n} - \hat{y}_{n} \right| $$which we could accomplish with a computer program. The resulting dashed line in Figure 8.12 shows this fit can be quite reasonable. However, a more common practice is to choose the line that minimizes the sum of the squared residuals:
$$ \left(y_{1} - \hat{y}_{1}\right)^{2} + \left(y_{2} - \hat{y}_{2}\right)^{2} + \dots + \left(y_{n} - \hat{y}_{n}\right)^{2} $$The line that minimizes the sum of the squared residuals is represented as the solid line in Figure 8.12. This is commonly called the least squares line.
Both lines seem reasonable, so why do data scientists prefer the least squares regression line? One reason is that it is easier to compute by hand and in most statistical software. Another, more compelling, reason is that in many applications a residual twice as large as another residual is more than twice as bad. For example, being off by 4 is usually more than twice as bad as being off by 2. Squaring the residuals accounts for this discrepancy.
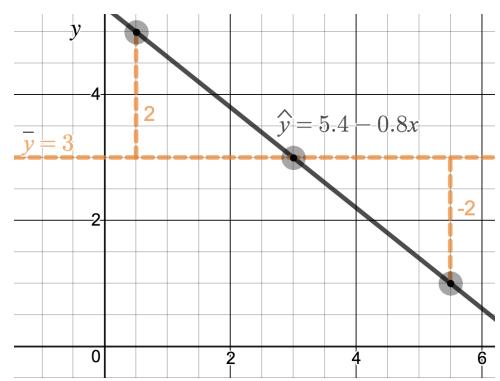
In Figure 8.13, we imagine the squared error about a line as actual squares. The least squares regression line minimizes the sum of the areas of these squared errors. In the figure, the sum of the squared error is \(4 + 1 + 1 = 6\). There is no other line about which the sum of the squared error will be smaller.
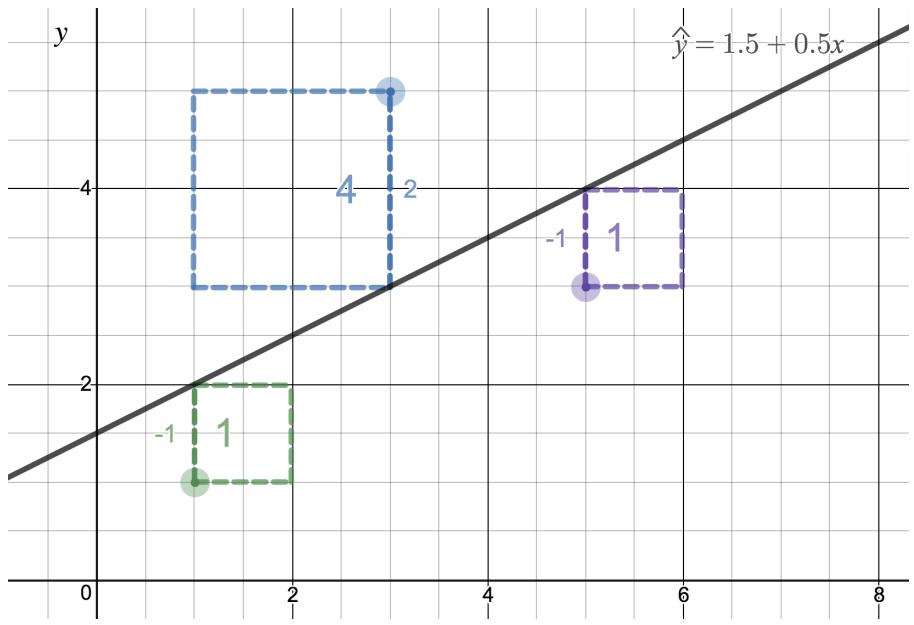
Figure 8.13: A visualization of least squares regression using Desmos. Try out this and other interactive Desmos activities at openintro.org/ahss/desmos.
The choice between "sum of absolute residuals" and "sum of squared residuals" is a choice about what kind of mistakes hurt most. Squared error says large misses should be punished disproportionately — a single bad miss of 10 counts as much as 100 small misses of 1. If you were picking a line for a safety-critical setting (medical dosing, structural engineering), that punishment is exactly what you want: avoid the rare catastrophic miss even at the cost of more small misses.
"Least squares" is not a statement about what is true — it is a statement about what is computable and defensible. The line has no magical claim to reality; it is simply the line with the smallest sum of squared vertical gaps. The appeal is that two analysts working with the same data will compute exactly the same line, every time. That reproducibility is worth a lot more than "fitting by eye."
Source: Main Text
Suppose you have four data points and two candidate lines. The residuals from Line A are \(+2, -3, +1, -2\). The residuals from Line B are \(+5, 0, 0, -1\).
(a) Compute the sum of absolute residuals for each line. Which line is "best" by that criterion? (b) Compute the sum of squared residuals for each line. Which line is "best" by least squares? (c) Explain in one sentence why the two criteria might pick different winners.
Solution
(a) Sum of absolute residuals: - Line A: \(|{+2}| + |{-3}| + |{+1}| + |{-2}| = 2 + 3 + 1 + 2 = 8\). - Line B: \(|{+5}| + |0| + |0| + |{-1}| = 5 + 0 + 0 + 1 = 6\).
Line B wins on absolute residuals.
(b) Sum of squared residuals: - Line A: \(2^2 + (-3)^2 + 1^2 + (-2)^2 = 4 + 9 + 1 + 4 = 18\). - Line B: \(5^2 + 0^2 + 0^2 + (-1)^2 = 25 + 0 + 0 + 1 = 26\).
Line A wins on squared residuals.
(c) The squared-residual criterion penalizes big misses disproportionately. Line B has one miss of size 5 (squared = 25), which outweighs Line A's worst miss of 3 (squared = 9) even though Line A has more total misses.
8.2.2 Finding the Least Squares Line
For the Elmhurst College data, we could fit a least squares regression line for predicting gift aid based on a student's family income and write the equation as:
$$ \widehat{aid} = a + b \times \text{family\_income} $$Here \(a\) is the \(y\)-intercept of the least squares regression line and \(b\) is the slope of the least squares regression line. \(a\) and \(b\) are both statistics that can be calculated from the data. In the next section we will consider the corresponding population parameters that these statistics attempt to estimate.
We can enter all the data into a statistical software package and easily find the values of \(a\) and \(b\). However, we can also calculate these values by hand, using only the summary statistics:
- The slope of the least squares line is given by
where \(r\) is the correlation between the variables \(x\) and \(y\), and \(s_{x}\) and \(s_{y}\) are the sample standard deviations of \(x\) (the explanatory variable) and \(y\) (the response variable).
- The point of averages \((\bar{x}, \bar{y})\) is always on the least squares line. Plugging this point in for \(x\) and \(y\) in the least squares equation and solving for \(a\) gives:
Finding the Slope and Intercept of the Least Squares Regression Line
The least squares regression line for predicting \(y\) based on \(x\) can be written as \(\hat{y} = a + bx\), with:
$$ b = r\,\frac{s_{y}}{s_{x}} \qquad a = \bar{y} - b\,\bar{x} $$We first find \(b\), the slope, and then we solve for \(a\), the \(y\)-intercept.
Identifying the Least Squares Line from Summary Statistics
To identify the least squares line from summary statistics:
- Estimate the slope parameter: \(b_{1} = (s_{y}/s_{x})\,R\).
- Noting that the point \((\bar{x}, \bar{y})\) is on the least squares line, use \(x_{0} = \bar{x}\) and \(y_{0} = \bar{y}\) with the point-slope equation: \(y - \bar{y} = b_{1}(x - \bar{x})\).
- Simplify the equation, which reveals that \(b_{0} = \bar{y} - b_{1}\,\bar{x}\).
Source: Main Text
Figure 8.14 shows the sample means for the family income and gift aid as \$101,800 and \$19,940, respectively. Plot the point \((101.8, 19.94)\) on Figure 8.12 to verify it falls on the least squares line (the solid line).
Solution
The point of averages \((\bar{x}, \bar{y}) = (101.8, 19.94)\) must lie on the least squares line, because the line is constructed so that \(a = \bar{y} - b\,\bar{x}\), i.e. \(\bar{y} = a + b\,\bar{x}\). If you plot \((101.8, 19.94)\) on Figure 8.12 and visually check, the point lies exactly on the solid line (the least squares line). This is a universal property of least squares regression, not a coincidence.
Figure 8.14: Summary statistics for family income and gift aid.
| family income, in \$1,000s ("x") | gift aid, in \$1,000s ("y") | |
| mean | x̄ = 101.8 | ȳ = 19.94 |
| sd | sx = 63.2 | sy = 5.46 |
| r = -0.499 |
Source: Main Text
Using the summary statistics in Figure 8.14, find the equation of the least squares regression line for predicting gift aid based on family income.
Solution
Step 1 — Compute the slope \(b\) using \(b = r \cdot s_y/s_x\):
$$ b = r\,\frac{s_{y}}{s_{x}} = (-0.499)\,\frac{5.46}{63.2} = -0.0431. $$Step 2 — Compute the intercept \(a\) using \(a = \bar{y} - b\,\bar{x}\):
$$ a = \bar{y} - b\,\bar{x} = 19.94 - (-0.0431)(101.8) = 19.94 + 4.388 = 24.3. $$Step 3 — Write out the equation of the least squares line:
$$ \hat{y} = 24.3 - 0.0431\,x \qquad \text{or} \qquad \widehat{aid} = 24.3 - 0.0431 \times \text{family\_income}. $$Source: Main Text
Using the summary statistics in Figure 8.14, compute the slope for the regression line of gift aid against family income.
Solution
Using \(b = r \cdot s_y/s_x\):
$$ b = (-0.499)\,\frac{5.46}{63.2} = -0.04311\ldots \approx -0.0431. $$The slope is \(-0.0431\). (It matches Example 8.2.1 — that is intentional; Guided Practice 8.10 is the "show your work" version of Example 8.2.1's first line.)
You might recall the point-slope form of a line from algebra. Given the slope of a line and a point on the line \((x_{0}, y_{0})\), the equation for the line can be written as:
$$ y - y_{0} = \text{slope} \times (x - x_{0}). $$Source: Main Text
Using the point \((101{,}780,\, 19{,}940)\) from the sample means (measured in raw dollars rather than \$1,000s) and the slope estimate \(b_{1} = -0.0431\) from Guided Practice 8.10, find the least-squares line for predicting aid based on family income.
Solution
Step 1 — Apply the point-slope equation with \((x_0, y_0) = (101{,}780, 19{,}940)\) and \(b_1 = -0.0431\):
$$ y - y_{0} = b_{1}(x - x_{0}) $$ $$ y - 19{,}940 = -0.0431\,(x - 101{,}780). $$Step 2 — Expand the right side:
$$ y - 19{,}940 = -0.0431\,x + 0.0431 \times 101{,}780 = -0.0431\,x + 4{,}386.7. $$Step 3 — Add 19,940 to both sides to isolate \(y\):
$$ y = -0.0431\,x + 4{,}386.7 + 19{,}940 = 24{,}326.7 - 0.0431\,x. $$The equation simplifies to:
$$ \widehat{aid} = 24{,}327 - 0.0431 \times \text{family\_income}. $$Here we have replaced \(y\) with \(\widehat{aid}\) and \(x\) with family income to put the equation in context. The final equation should always include a "hat" on the variable being predicted, whether it is a generic \(y\) or a named variable like "aid."
A computer is usually used to compute the least squares line, and a summary table generated using software for the Elmhurst regression line is shown in Figure 8.15. The first column of numbers provides estimates for \(b_{0}\) (the intercept) and \(b_{1}\) (the slope), respectively. These results match Example 8.2.1 (with minor rounding).
Figure 8.15: Summary of least squares fit for the Elmhurst data (raw dollar units). Compare the parameter estimates in the first column to the results of Example 8.2.2.
| Estimate | Std. Error | t value | Pr(>|t|) | |
| (Intercept) | 24319.3 | 1291.5 | 18.83 | <0.0001 |
| family_income | -0.0431 | 0.0108 | -3.98 | 0.0002 |

Source: Main Text
Say we wanted to predict a student's family income based on the amount of gift aid received. Would the least squares regression line be the following?
$$ aid = 24.3 - 0.0431 \times \text{family\_income} $$Solution
No. The equation we found was for predicting aid, not for predicting family income. To predict family income from aid, we must calculate a new regression line — letting \(y\) be family income and \(x\) be aid.
Step 1 — Recompute the slope with the roles of \(x\) and \(y\) swapped:
$$ b = r\,\frac{s_{y}}{s_{x}} = (-0.499)\,\frac{63.2}{5.46} = -5.776. $$Step 2 — Recompute the intercept (note \(\bar{y}\) is now family income's mean, 101.8, and \(\bar{x}\) is aid's mean, 19.94):
$$ a = \bar{y} - b\,\bar{x} = 101.8 - (-5.776)(19.94) = 101.8 + 115.17 = 216.97 \approx 217. $$The fitted line for predicting family income from aid is therefore:
$$ \widehat{\text{family\_income}} = 217 - 5.776 \times aid $$in units of \$1,000s. (The source prints 607.3 here due to a typo — the correct arithmetic yields roughly 217 for the intercept.) The key lesson is that swapping explanatory and response variables produces a different regression line, not the algebraic inverse of the original.
A summary table based on computer output is shown in Figure 8.16 for the Elmhurst College data in \$1,000 units. The first column of numbers provides estimates for \(b_{0}\) and \(b_{1}\), respectively.
Figure 8.16: Summary of least squares fit for the Elmhurst College data (in \$1,000s). Compare the parameter estimates in the first column to Example 8.2.1.
| Estimate | Std. Error | t value | Pr(>|t|) | |
| (Intercept) | 24.3193 | 1.2915 | 18.83 | 0.0000 |
| family_income | -0.0431 | 0.0108 | -3.98 | 0.0002 |
Source: Main Text
Examine the second, third, and fourth columns in Figure 8.16. Can you guess what they represent?
Solution
We focus on the second row (the slope).
- First column (Estimate = −0.0431): our best estimate for the slope of the population regression line. We call this point estimate \(b\). - Second column (Std. Error = 0.0108): the standard error of this point estimate — how much the estimate would be expected to vary if we drew repeated samples of fifty freshmen. - Third column (t value = −3.98): the \(t\) test statistic for the null hypothesis that the slope of the population regression line is zero, computed as \(\text{Estimate}/\text{Std. Error} = -0.0431/0.0108 = -3.98\). - Fourth column (Pr(>|t|) = 0.0002): the p-value for a two-sided \(t\)-test of that null hypothesis. A p-value this small is strong evidence that the true slope is not zero.
We will get into more details in Section 8.4.
Source: Main Text
What do the first and second columns of Figure 8.17 (below) represent, for a hypothetical regression of seat changes on unemployment rate?
$$ \hat{y} = -7.3644 - 0.8897\,x $$where \(\hat{y}\) is the predicted change in the number of seats for the president's party, and \(x\) represents the unemployment rate.
Solution
The entries in the first column represent the least squares estimates \(b_{0}\) and \(b_{1}\), and the values in the second column correspond to the standard errors of each estimate. Using the estimates, we can write the regression line as shown above.
We previously used a \(t\)-test statistic for hypothesis testing in the context of numerical data. Regression is very similar. Since the null value for the slope is 0, the test statistic is:
$$ T = \frac{\text{estimate} - \text{null value}}{\text{SE}} = \frac{-0.8897 - 0}{0.8350} = -1.07. $$This corresponds to the third column of the regression table.
Source: Main Text
Suppose a high school senior is considering Elmhurst College. Can she simply use the linear equation we have found to calculate her financial aid from the university?
Solution
No. Using the equation will provide a prediction or estimate, not a guarantee. As we see in the scatterplot, there is a lot of variability around the line. While the linear equation is good at capturing the trend in the data, there will be significant error in predicting an individual student's aid. Additionally, the data all come from one freshman class, and the way aid is determined by the university may change from year to year. A prediction for a current senior is a rough extrapolation of last year's aid policy.
Source: Main Text
A different college has summary statistics \(\bar{x} = 80\) (family income, in \$1,000s), \(\bar{y} = 15\) (gift aid, in \$1,000s), \(s_x = 50\), \(s_y = 4\), and \(r = -0.6\).
(a) Compute the slope of the least squares regression line for predicting gift aid from family income. (b) Compute the \(y\)-intercept. (c) Write out the regression equation \(\widehat{aid} = a + b \times \text{family\_income}\).
Solution
(a) Slope:
$$ b = r \cdot \frac{s_y}{s_x} = (-0.6) \cdot \frac{4}{50} = -0.048. $$(b) Intercept:
$$ a = \bar{y} - b\,\bar{x} = 15 - (-0.048)(80) = 15 + 3.84 = 18.84. $$(c) Regression equation:
$$ \widehat{aid} = 18.84 - 0.048 \times \text{family\_income} \quad (\text{in \$1,000s}). $$Notice how little work \(b = r\,s_y/s_x\) actually does: three summary numbers go in, one slope comes out. You do not need the individual data points — just the correlation and the two standard deviations. That is why 19th-century statisticians (long before computers) could fit regression lines by hand for problems in astronomy and biology. Every modern regression tool does exactly the same calculation, just faster.
The slope formula \(b = r\,s_y/s_x\) is a unit-conversion machine in disguise. Think of \(s_y/s_x\) as "how many units of \(y\) correspond to one standard deviation of \(x\)", and \(r\) as "how strongly the two variables move together." Multiply them and you get "units of \(y\) per unit of \(x\) along the line of best fit" — which is exactly the slope.
8.2.3 Interpreting the Coefficients of a Regression Line
Interpreting the coefficients in a regression model is often one of the most important steps in the analysis. A number without interpretation is just a number; in context, the same number is a prediction, an effect size, a policy claim.
Source: Main Text
The slope for the Elmhurst College data for predicting gift aid based on family income was calculated as \(-0.0431\). Interpret this quantity in the context of the problem.
Solution
You might recall from algebra that slope is change in \(y\) over change in \(x\). Here, both \(x\) and \(y\) are in thousands of dollars. So if \(x\) is one unit (one thousand dollars) higher, the line predicts \(y\) will change by \(-0.0431\) thousand dollars. In other words: for each additional thousand dollars of family income, on average, students receive \(0.0431\) thousand — about \$43.10 — less in gift aid. A higher family income corresponds to less aid because the slope is negative.
Source: Main Text
Examine Figure 8.16, which relates the Elmhurst College aid and student family income. How sure are you that the slope is statistically significantly different from zero? That is, do you think a formal hypothesis test would reject the claim that the true slope of the line should be zero?
Solution
While the relationship between the variables is not perfect, there is an evident decreasing trend in the data. The p-value in Figure 8.16 is \(0.0002\), which is far below any conventional threshold (like \(0.05\) or \(0.01\)). This strongly suggests the hypothesis test will reject the null claim that the slope is zero.
Source: Main Text
The \(y\)-intercept for the Elmhurst College data for predicting gift aid based on family income was calculated as \(24.3\). Interpret this quantity in the context of the problem.
Solution
The intercept \(a\) describes the predicted value of \(y\) when \(x = 0\). The predicted gift aid is \(24.3\) thousand dollars if a student's family has no income. The meaning of the intercept is relevant to this application because the family income for some students at Elmhurst is \$0. In other applications, the intercept may have little or no practical value if there are no observations where \(x\) is near zero. Here, it would be acceptable to say that the average gift aid is \$24,300 among students whose families have \$0 in income.
Interpreting Coefficients in a Linear Model
- The slope, \(b\), describes the average increase or decrease in the \(y\) variable if the explanatory variable \(x\) is one unit larger.
- The \(y\)-intercept, \(a\), describes the predicted outcome of \(y\) if \(x = 0\). The linear model must be valid all the way to \(x = 0\) for this interpretation to make sense, which in many applications is not the case.
Interpreting Parameters Estimated by Least Squares
The slope describes the estimated difference in the \(y\) variable if the explanatory variable \(x\) for a case happened to be one unit larger. The intercept describes the average outcome of \(y\) if \(x = 0\) and the linear model is valid all the way to \(x = 0\), which in many applications is not the case.
Source: Main Text
In the previous chapter, we encountered a data set that compared the price of new textbooks for UCLA courses at the UCLA Bookstore and on Amazon. We fit a linear model for predicting price at UCLA Bookstore from price on Amazon and get:
$$ \hat{y} = 1.86 + 1.03\,x $$where \(x\) is the price on Amazon (in dollars) and \(y\) is the price at the UCLA bookstore (in dollars). Interpret the coefficients in this model and discuss whether the interpretations make sense in this context.
Solution
Slope (\(b = 1.03\)): For each additional \$1.00 in the Amazon price of a textbook, the UCLA Bookstore price is about \$1.03 higher on average. This makes sense — books that cost more at one vendor also tend to cost more at the other.
Intercept (\(a = 1.86\)): If Amazon's price were \$0, the UCLA Bookstore price would be predicted to be \$1.86. Since a \$0 Amazon price is essentially outside the realistic data range, this intercept has limited practical meaning — it is a mathematical artifact used to make the line line up with the data.
Both interpretations make sense as descriptions of the fitted line; only the slope has real-world applicability to typical textbook prices.
Source: Main Text
Can we conclude that if Amazon raises the price of a textbook by \$1.00, the UCLA Bookstore will raise the price of the textbook by \$1.03?
Solution
No. The slope describes an average cross-sectional relationship — looking across many textbooks at one point in time, the UCLA Bookstore prices are on average \$1.03 higher for each extra \$1.00 in Amazon price. That is not the same as a causal, dynamic response of one vendor's pricing to another's. If Amazon raises a specific textbook's price by \$1.00 tomorrow, there is no guarantee the UCLA Bookstore will do anything in response. The slope is a description of the pattern in the data, not a prediction of vendor behavior.
Exercise Caution When Interpreting Coefficients of a Linear Model
- The slope tells us only the average change in \(y\) for each unit change in \(x\); it does not tell us how much \(y\) might change based on a change in \(x\) for any particular individual. Moreover, in most cases, the slope cannot be interpreted in a causal way.
- When a value of \(x = 0\) doesn't make sense in an application, the interpretation of the \(y\)-intercept won't have any practical meaning.
The difference between "the slope is \(-0.0431\)" and "for every extra \$1,000 of family income, the average aid drops by about \$43" is everything. The first is an artifact of the regression. The second is a sentence a student, a parent, or a financial-aid officer can actually use. In practice, interpreting coefficients in plain English is the whole point of fitting a regression in the first place.
A very common mistake is turning a cross-sectional slope into a causal policy claim — "if we cut family income by \$1,000, aid will go up by \$43 on average." That claim requires more than regression can deliver, because confounders (grades, legacy status, major, demonstrated financial need) may be driving both variables. Correlation is not causation, and slope is a numerical summary of correlation. Never treat \(b\) as a policy lever without an experimental design to back it up.
Source: Main Text
A regression of a child's shoe size \(y\) on age (in years) \(x\) gives \(\hat{y} = 3 + 0.8\,x\) for children aged 4 to 12.
(a) Interpret the slope in plain English. (b) Interpret the \(y\)-intercept. Does it have practical meaning? (c) Would you use this equation to predict the shoe size of a newborn (age 0)? Why or why not?
Solution
(a) For each additional year of age, a child's shoe size increases by \(0.8\) on average.
(b) The intercept is \(3\), which is the predicted shoe size at age \(0\). Since the data only cover ages 4 to 12, this intercept has no practical meaning — babies do not wear "size 3" shoes that fit the adult/child shoe-sizing scale used here. It is a mathematical anchor for the line, not a real prediction.
(c) No. Age \(0\) is outside the range of the data (ages 4 to 12). Predicting for a newborn would be extrapolation, which is unreliable — see the next subsection.
8.2.4 Extrapolation Is Treacherous
When those blizzards hit the East Coast this winter, it proved to my satisfaction that global warming was a fraud. That snow was freezing cold. But in an alarming trend, temperatures this spring have risen. Consider this: On February \(6^{\text{th}}\) it was 10 degrees. Today it hit almost 80. At this rate, by August it will be 220 degrees. So clearly folks the climate debate rages on.
— Stephen Colbert, April 6, 2010
Linear models can be used to approximate the relationship between two variables. However, these models have real limitations. Linear regression is simply a modeling framework. The truth is almost always much more complex than a simple line. For example, we do not know how the data outside of our limited window will behave.
Source: Main Text
Use the model \(\widehat{aid} = 24.3 - 0.0431 \times \text{family\_income}\) to estimate the aid of another freshman student whose family had income of \$1 million.
Solution
Step 1 — Convert the income into the model's units. The units of family income are \$1,000s, so \$1,000,000 becomes \(\text{family\_income} = 1000\).
Step 2 — Plug into the model:
$$ \widehat{aid} = 24.3 - 0.0431(1000) = 24.3 - 43.1 = -18.8. $$The model predicts this student will have \(-\$18{,}800\) in aid — that is, the student would pay \$18,800 on top of tuition. Elmhurst College cannot (or at least does not) require students with high-income families to pay extra on top of tuition to attend. The prediction is obviously ridiculous.
Using a model to predict \(y\)-values for \(x\)-values outside the domain of the original data is called extrapolation. Generally, a linear model is only an approximation of the real relationship between two variables. If we extrapolate, we are making an unreliable bet that the approximate linear relationship will be valid in places where it has not been analyzed.
Extrapolation Warning
A regression line is valid only within the range of the data used to fit it. Outside that range, the line is a guess, and guesses compound the farther you go. A model that is excellent at predicting within the data can be catastrophically wrong outside it.
The Colbert quote above is a joke, but the joke works because extrapolation is a real mistake that real people make all the time — projecting short-term trends (spring warming, stock returns, COVID case counts) forward indefinitely and getting apocalyptic or utopian predictions. The math of a line says "just plug in any \(x\)," but the data says "we only looked at \(x\) in this range." When those two disagree, trust the data.
A good check: before you plug an \(x\) into a regression equation, ask "is this \(x\) close to values that were actually in the data?" If not, do not trust the prediction. If you must extrapolate, at minimum acknowledge it explicitly, widen your uncertainty, and think about what physical or economic constraints the line is ignoring (like "aid cannot be negative").
Source: Main Text
Suppose a regression of temperature \(y\) in degrees Fahrenheit on calendar date \(x\) (from February 6th through April 6th in the Colbert quote) gives \(\hat{y} = 10 + 1.17\,x\), where \(x\) is the number of days after February 6th.
(a) Predict the temperature on April 6th (\(x = 59\) days). Does this match the quote? (b) Use the model to "predict" the temperature on August 6th (\(x = 181\) days). (c) Why is the answer in part (b) nonsense, and what is the correct name for this mistake?
Solution
(a) \(\hat{y} = 10 + 1.17 \times 59 = 10 + 69.03 = 79.03 \approx 80\) degrees. This matches the quote exactly.
(b) \(\hat{y} = 10 + 1.17 \times 181 = 10 + 211.77 = 221.77 \approx 222\) degrees — very close to Colbert's "220 degrees."
(c) Temperatures do not rise monotonically from February through August — they peak in July and fall again. The linear model was fit to two months of data and has no information about the summer's seasonal peak or fall's cooling. Using the equation for August is extrapolation, and the prediction is ridiculous.
8.2.5 Using R-squared to Describe the Strength of a Fit
We evaluated the strength of the linear relationship between two variables earlier using the correlation, \(r\). However, it is more common to explain the fit of a model using \(R^2\), called R-squared or the explained variance. If provided with a linear model, we might want to describe how closely the data cluster around the linear fit.
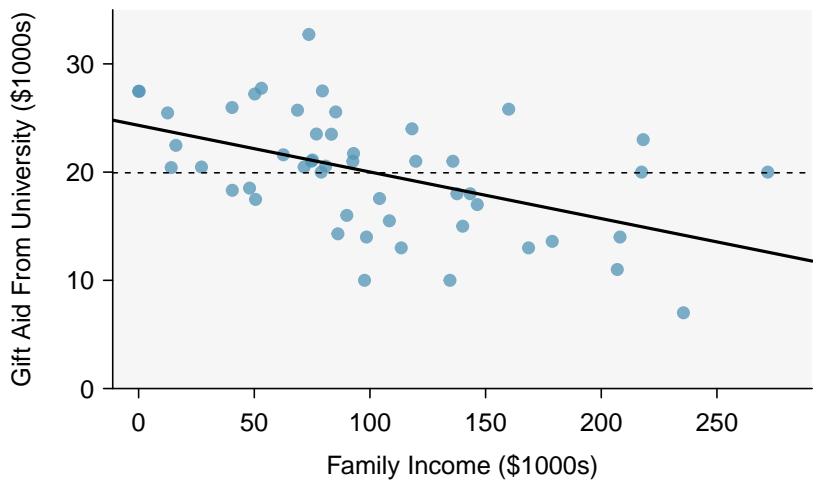
Figure 8.17: Gift aid and family income for a random sample of 50 freshman students from Elmhurst College, shown with the least squares regression line \(\hat{y}\) and the average line \(\bar{y}\).
We are interested in how well a model accounts for, or explains, the location of the \(y\) values. The \(R^2\) of a linear model describes how much smaller the variance (in the \(y\) direction) about the regression line is than the variance about the horizontal line \(\bar{y}\). For the Elmhurst College data shown in Figure 8.17, the variance of the response variable (aid received) is
$$ s_{aid}^{2} = 29.8. $$If we apply our least squares line, the variability in the residuals describes how much variation remains after using the model:
$$ s_{RES}^{2} = 22.4. $$The reduction in the variance is:
$$ \frac{s_{aid}^{2} - s_{RES}^{2}}{s_{aid}^{2}} = \frac{29.8 - 22.4}{29.8} = \frac{7.4}{29.8} \approx 0.25. $$(Roughly 25% of the variance in aid is explained by family income.) If we used the simple standard deviation of the residuals, this computation would give exactly \(R^2\). However, the standard way of computing the standard deviation of the residuals is slightly more sophisticated. To avoid any trouble, we can instead use a sum of squares method. If we call the sum of the squared errors about the regression line \(SSRes\) and the sum of the squared errors about the mean \(SSM\), we can define \(R^2\) as:
$$ R^{2} = \frac{SSM - SSRes}{SSM} = 1 - \frac{SSRes}{SSM}. $$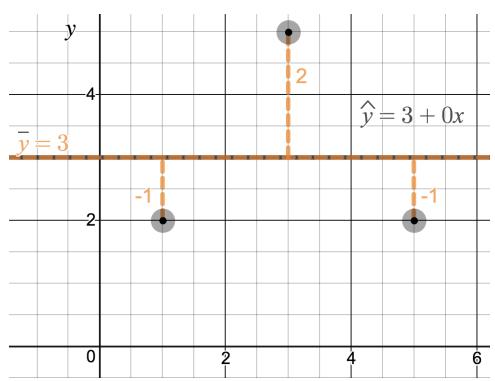
(a)
(b)
Figure 8.18: (a) The regression line is equivalent to \(\bar{y}\); \(R^{2} = 0\). (b) The regression line passes through all of the points; \(R^{2} = 1\). Try out this and other interactive Desmos activities at openintro.org/ahss/desmos.

Source: Main Text
Using the formula for \(R^2\), confirm that in Figure 8.18 (a), \(R^{2} = 0\), and that in Figure 8.18 (b), \(R^{2} = 1\).
Solution
(a) Regression line equals \(\bar{y}\): If the regression line is horizontal at \(\bar{y}\), then every prediction \(\hat{y}_i = \bar{y}\), and the residuals are \(y_i - \hat{y}_i = y_i - \bar{y}\). So \(SSRes = \sum(y_i - \bar{y})^2 = SSM\). Therefore:
$$ R^{2} = 1 - \frac{SSRes}{SSM} = 1 - \frac{SSM}{SSM} = 1 - 1 = 0. $$(b) Regression line passes through all points: Every \(\hat{y}_i = y_i\), so every residual is \(0\), meaning \(SSRes = 0\). Therefore:
$$ R^{2} = 1 - \frac{0}{SSM} = 1 - 0 = 1. $$\(R^2\) Is the Explained Variance
\(R^{2}\) is always between \(0\) and \(1\), inclusive. It tells us the proportion of variation in the \(y\) values that is explained by a regression model. The higher the value of \(R^{2}\), the better the model "explains" the response variable.
The value of \(R^{2}\) is, in fact, equal to \(r^{2}\), where \(r\) is the correlation. This means that \(r = \pm\sqrt{R^{2}}\). Use this fact to answer the next two practice problems.

Source: Main Text
If a linear model has a very strong negative relationship with a correlation of \(-0.97\), how much of the variation in the response variable is explained by the linear model?
Solution
Since \(R^2 = r^2\):
$$ R^{2} = (-0.97)^{2} = 0.9409. $$About \(94\%\) of the variation in the response variable is explained by the linear model. (Very strong relationships translate into very high \(R^2\) values — squaring a number close to \(\pm 1\) stays close to 1.)

Source: Main Text
If a linear model has an \(R^{2}\) or explained variance of \(0.94\), what is the correlation?
Solution
Since \(r = \pm\sqrt{R^{2}}\):
$$ r = \pm\sqrt{0.94} \approx \pm 0.970. $$The sign of \(r\) is whatever the slope's sign is. If the regression line has a positive slope, \(r \approx +0.97\); if negative, \(r \approx -0.97\). Without the scatterplot or the slope, we cannot decide the sign from \(R^2\) alone.
Reporting \(R^2 = 0.25\) is a more actionable statement than reporting "\(r = -0.499\)." Both are correct, but \(R^2\) gives a proportion — "this model explains 25% of the variation in aid, leaving 75% unexplained." That framing helps a reader decide whether the model is good enough for their purpose, or whether they need to collect more variables (a multivariable regression in Chapter 9).
\(R^2\) has a well-known nickname in machine learning and economics: coefficient of determination. It answers the question "how much of what is going on in \(y\) is captured by the model?" If \(R^2 = 0.95\), the model is doing almost all the work; if \(R^2 = 0.05\), the model is barely doing any. A high \(R^2\) is not a guarantee that the model is correct (Anscombe's Quartet from Section 8.1 has \(R^2 \approx 0.67\) for four very different datasets), but low \(R^2\) is a guarantee that something important is missing.
Source: Main Text
A regression of a student's final exam score \(y\) on their midterm score \(x\) produces \(r = 0.80\).
(a) Compute \(R^2\) and interpret it in context. (b) What percentage of the variation in final exam scores is not explained by midterm scores? (c) If a different class gives \(R^2 = 0.49\), what would be the correlation (assuming a positive slope)?
Solution
(a) \(R^2 = 0.80^2 = 0.64\). About 64% of the variation in final exam scores is explained by the linear regression on midterm scores.
(b) \(1 - R^2 = 1 - 0.64 = 0.36\), so 36% of the variation in final exam scores is unexplained — it must come from other factors (study habits, different topics on the final, test-day performance, etc.).
(c) \(r = \sqrt{0.49} = 0.70\) (positive by assumption). A weaker relationship than the first class.
8.2.6 Technology: Linear Correlation and Regression
Get started quickly with the Desmos LinReg Calculator (available at openintro.org/ahss/desmos).
Calculator Instructions

TI-84: Finding \(a\), \(b\), \(R^2\), and \(r\) for a Linear Model
Use
STAT,CALC,LinReg(a + bx).1. Press
STAT.2. Right arrow to
CALC.3. Down arrow and choose
8:LinReg(a+bx).- Caution: choosing
4:LinReg(ax+b)will reverse \(a\) and \(b\).4. Let
XlistbeL1andYlistbeL2(enter the \(x\) and \(y\) values in L1 and L2 first).5. Leave
FreqListblank.6. Leave
Store RegEQblank.7. Choose
Calculateand hitENTER, which returns:-
a— the \(y\)-intercept of the best fit line-
b— the slope of the best fit line-
r²— \(R^2\), the explained variance-
r— the correlation coefficientTI-83: Do steps 1-3, then enter the \(x\) list and \(y\) list separated by a comma, e.g.
LinReg(a+bx) L1, L2, then hitENTER.
What to Do If \(R^2\) and \(r\) Do Not Show Up on a TI-83/84
If \(r^2\) and \(r\) do not show up when doing
STAT,CALC,LinReg, diagnostics must be turned on. This only needs to be done once and the diagnostics will remain on.1. Hit
2ND 0(i.e.CATALOG).2. Scroll down until the arrow points at
DiagnosticOn.3. Hit
ENTERandENTERagain. The screen should now say:
DiagnosticOn
Done
What to Do If a TI-83/84 Returns: `ERR: DIM MISMATCH`
This error means that the lists, generally L1 and L2, do not have the same length.
1. Choose
1:Quit.2. Choose
STAT,Editand make sure that the lists have the same number of entries.

Casio fx-9750GII: Finding \(a\), \(b\), \(R^2\), and \(r\) for a Linear Model
1. Navigate to
STAT(MENUbutton, then hit the2button or selectSTAT).2. Enter the \(x\) and \(y\) data into 2 separate lists, e.g. \(x\) values in List 1 and \(y\) values in List 2. Observation ordering should be the same in the two lists. For example, if \((5, 4)\) is the second observation, then the second value in the \(x\) list should be 5 and the second value in the \(y\) list should be 4.
3. Navigate to
CALC(F2) and thenSET(F6) to set the regression context.- To change the 2Var XList, navigate to it, select
List(F1), and enter the proper list number. Similarly, set 2Var YList to the proper list.4. Hit
EXIT.5. Select
REG(F3),X(F1), anda+bx(F2), which returns:-
a— the \(y\)-intercept of the best fit line-
b— the slope of the best fit line-
r— the correlation coefficient-
r²— \(R^2\), the explained variance-
MSe— Mean squared error, which you can ignoreIf you select
ax+b(F1), the \(a\) and \(b\) meanings will be reversed.
Source: Main Text
The data set loan50, introduced in Chapter 1, contains information on randomly sampled loans offered through Lending Club. A subset of the data matrix is shown in Figure 8.19. Use a calculator to find the equation of the least squares regression line for predicting loan amount from total income based on this subset.

Figure 8.19: Sample of data from loan50.
| total_income | loan_amount | |
| 1 | 59000 | 22000 |
| 2 | 60000 | 6000 |
| 3 | 75000 | 25000 |
| 4 | 75000 | 6000 |
| 5 | 254000 | 25000 |
| 6 | 67000 | 6400 |
| 7 | 28800 | 3000 |
Solution
Entering total_income in L1 and loan_amount in L2 on a TI-84 and running LinReg(a+bx) gives approximately:
- \(a \approx 8{,}863\) - \(b \approx 0.042\) - \(r \approx 0.27\) - \(R^2 \approx 0.07\)
So the fitted line is approximately:
$$ \widehat{\text{loan\_amount}} = 8{,}863 + 0.042 \times \text{total\_income}. $$(Exact values depend on the software's rounding and the exact rows used; answers within \(\pm 10\%\) of these are acceptable.) The low \(R^2\) tells us that total income explains only about 7% of the variation in loan amount for this small sample — most of the variation comes from other factors.
Calculator and software output is a safety net, not a replacement for the slope and intercept formulas. If you blindly press LinReg and get a line, you won't catch typos in your data, unit mismatches, or outliers that are pulling the line in a bad direction. Always plot the data first (STAT PLOT on a TI, geom_point() in ggplot, etc.) and check that the line makes sense before quoting it.
The labels on calculator output vary in confusing ways: some calculators show LinReg(ax+b) (slope first, intercept second) and some show LinReg(a+bx) (intercept first, slope second). Always confirm which label is which before writing down your equation. A regression line that says "\(\hat{y} = 0.042 + 8863\,x\)" instead of "\(\hat{y} = 8863 + 0.042\,x\)" is obviously wrong, but only if you notice the swap.
Source: Main Text
A calculator returns the following output after running a linear regression on five data points:
- \(a = 15.2\) - \(b = 2.5\) - \(r = 0.9\) - \(r^2 = 0.81\)
(a) Write the regression equation. (b) Interpret \(R^2\) in the context of this model. (c) What is the correlation \(r\), and what does its sign tell you about the scatterplot?
Solution
(a) \(\hat{y} = 15.2 + 2.5\,x\).
(b) About 81% of the variation in \(y\) is explained by the linear model. About 19% is left unexplained.
(c) \(r = 0.9\). The positive sign tells you that as \(x\) increases, \(y\) tends to increase — the scatterplot should show an upward-sloping pattern.
8.2.7 Types of Outliers in Linear Regression
Outliers in regression are observations that fall far from the "cloud" of points. These points are especially important because they can have a strong influence on the least squares line.
Source: Main Text
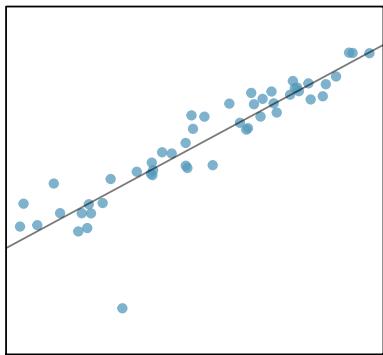
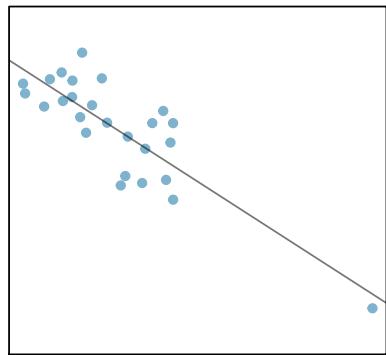
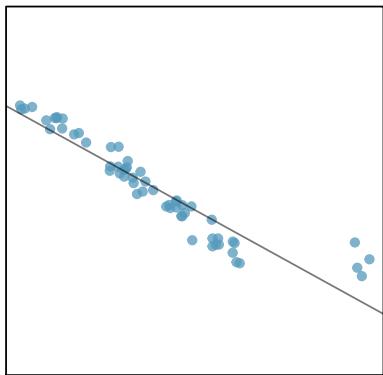
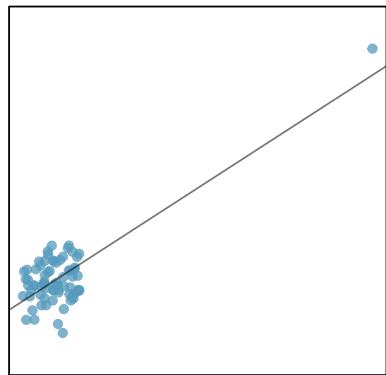
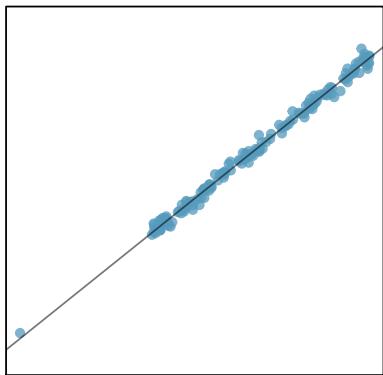
There are six plots shown in Figure 8.20 along with the least squares line and residual plots. For each scatterplot and residual plot pair, identify any obvious outliers and note how they influence the least squares line. Recall that an outlier is any point that doesn't appear to belong with the vast majority of the other points.
Solution
1. There is one outlier far from the other points, though it only appears to slightly influence the line. 2. There is one outlier on the right, though it is quite close to the least squares line, which suggests it wasn't very influential. 3. There is one point far away from the cloud, and this outlier appears to pull the least squares line up on the right; examine how the line around the primary cloud doesn't appear to fit very well. 4. There is a primary cloud and then a small secondary cloud of four outliers. The secondary cloud appears to be influencing the line somewhat strongly, making the least squares line fit poorly almost everywhere. There might be an interesting explanation for the dual clouds, which is something that could be investigated. 5. There is no obvious trend in the main cloud of points and the outlier on the right appears to largely control the slope of the least squares line. 6. There is one outlier far from the cloud, however, it falls quite close to the least squares line and does not appear to be very influential.
Examine the residual plots in Figure 8.20. You will probably find that there is some trend in the main clouds of (3) and (4). In these cases, the outliers influenced the slope of the least squares lines. In (5), data with no clear trend were assigned a line with a large trend simply due to one outlier.
Leverage
Points that fall horizontally away from the center of the cloud tend to pull harder on the line, so we call them points with high leverage. Points that fall horizontally far from the line are points of high leverage; these points can strongly influence the slope of the least squares line. If one of these high-leverage points appears to actually invoke its influence on the slope of the line — as in cases (3), (4), and (5) above — then we call it an influential point. Usually we can say a point is influential if, had we fitted the line without it, the influential point would have been unusually far from the least squares line.
It is tempting to remove outliers. Don't do this without a very good reason. Models that ignore exceptional (and interesting) cases often perform poorly. For instance, if a financial firm ignored the largest market swings — the "outliers" — it would soon go bankrupt by making poorly thought-out investments.
Don't Ignore Outliers When Fitting a Final Model
If there are outliers in the data, they should not be removed or ignored without a good reason. Whatever final model is fit to the data would not be very helpful if it ignores the most exceptional cases.
(1)
(2)
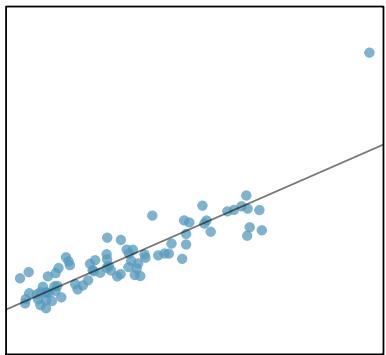
(3)
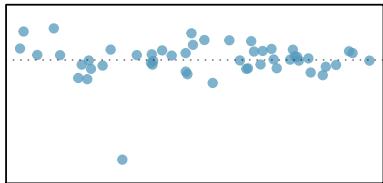
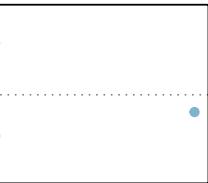
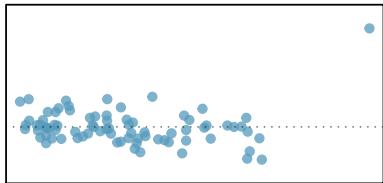
(4)
(5)
(6)
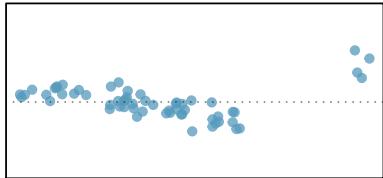

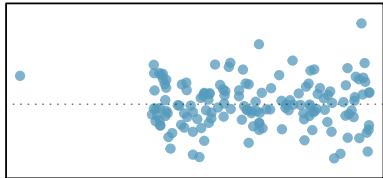
Figure 8.20: Six plots, each with a least squares line and residual plot. All data sets have at least one outlier.
Outlier Terminology
- Outlier: an observation that falls far from the bulk of the data.
- High-leverage point: a point with an \(x\)-value far from the center of the \(x\) distribution. High leverage does not imply high influence; a high-leverage point on the regression line can be harmless.
- Influential point: a high-leverage point whose removal would noticeably change the slope (or intercept) of the least squares line.
Outliers are one of the most common reasons a linear model is misleading. A single extreme observation can swing the slope, inflate or deflate \(R^2\), and make the line tell a different story than the bulk of the data. Always make a scatterplot before trusting a regression, and pay special attention to points at the extreme ends of the \(x\) range — those are the ones with the most leverage.
The decision to keep or drop an outlier is a scientific judgment, not a statistical one. A data-entry error or a malfunctioning sensor is a defensible reason to drop a point. "It doesn't fit my model" is not. When unsure, report the regression twice — once with the outlier and once without — and let the reader see how the result depends on that point.
Source: Main Text
A scatterplot shows 19 points in a tight upward line, plus one point far to the right of the cloud. Consider three candidates for this outlier:
- Candidate A: the outlier sits right on the line the other 19 points would produce. - Candidate B: the outlier sits far above the line the other 19 points would produce. - Candidate C: the outlier sits on the line of the 19 points but at \(x\) twice as far as any other \(x\).
For each candidate, classify the point as (i) high leverage, yes/no and (ii) influential, yes/no.
Solution
- Candidate A: Far right → high leverage yes. On the line → would not change the slope if removed → influential no. - Candidate B: Far right → high leverage yes. Off the line → removing it would visibly change the slope → influential yes. - Candidate C: Far right, on the line → high leverage yes, influential no (same reasoning as A).
Key takeaway: high leverage + far-from-line = influential. High leverage alone is not enough.
8.2.8 Categorical Predictors with Two Levels (Special Topic)
Categorical variables are also useful in predicting outcomes. Here we consider a categorical predictor with two levels (recall that a level is the same as a category). We'll consider eBay auctions for a video game, Mario Kart for the Nintendo Wii, where both the total price of the auction and the condition of the game were recorded. Here we want to predict total price based on game condition, which takes values used and new. A plot of the auction data is shown in Figure 8.21.
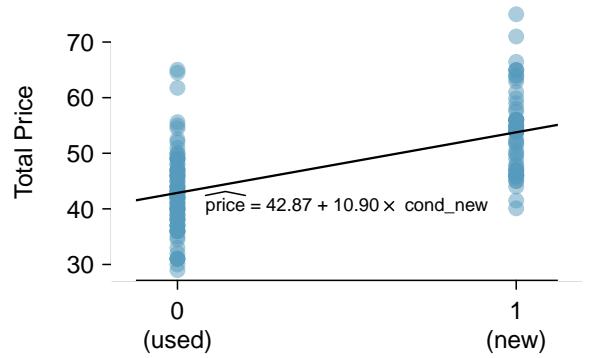
Figure 8.21: Total auction prices for the game Mario Kart, divided into used (\(x = 0\)) and new (\(x = 1\)) condition games with the least squares regression line shown.
Figure 8.22: Least squares regression summary for the Mario Kart data.
To incorporate the game condition variable into a regression equation, we must convert the categories into a numerical form. We do so using an indicator variable called cond_new, which takes value \(1\) when the game is new and \(0\) when the game is used. Using this indicator variable, the linear model may be written as:
The fitted model is summarized in the table below, and the model with its parameter estimates is given as:
$$ \widehat{price} = 42.87 + 10.90 \times \text{cond\_new}. $$For categorical predictors with two levels, the linearity assumption will always be satisfied. However, we must evaluate whether the residuals in each group are approximately normal with equal variance. Based on Figure 8.21, both of these conditions are reasonably satisfied.
| Estimate | Std. Error | t value | Pr(>|t|) | |
| (Intercept) | 42.87 | 0.81 | 52.67 | 0.0000 |
| cond_new | 10.90 | 1.26 | 8.66 | 0.0000 |
Source: Main Text
Interpret the two parameters estimated in the model for the price of Mario Kart in eBay auctions.
Solution
Intercept (\(\alpha = 42.87\)): The estimated price when cond_new takes value \(0\) — i.e. when the game is in used condition. The average selling price of a used version of the game is \$42.87.
Slope (\(\beta = 10.90\)): On average, new games sell for about \$10.90 more than used games. In this categorical setup, the slope is no longer a per-unit change — it is the group difference between the two levels of the categorical variable.
Interpreting Model Estimates for Categorical Predictors
The estimated intercept is the value of the response variable for the first category (the category corresponding to an indicator value of 0). The estimated slope is the average change in the response variable between the two categories.
Indicator variables are the bridge between categorical data and the regression machinery we built for numerical data. If you know how to handle the Mario Kart used-vs-new split, you can handle male-vs-female, treatment-vs-control, or AM-vs-PM. For categorical predictors with more than two levels (three genres, four cities, five brands), you add more indicator variables — one for each level except one "reference" level. Chapter 9 covers the details.
When a regression has only a single two-level categorical predictor, the slope equals the difference between the two group means. That is: \(\beta = \bar{y}_{\text{new}} - \bar{y}_{\text{used}}\). In this case, \$42.87 + \$10.90 = \$53.77 is the mean new-game price. The machinery of least squares reduces to an everyday "what's the gap between two group averages" calculation — a two-sample \(t\)-test in disguise.
Source: Main Text
A regression of a used car's selling price \(y\) (in \$1,000s) on whether the car has leather seats (leather = 1 for yes, 0 for no) gives:
(a) What is the average selling price of a car with no leather seats? (b) What is the average selling price of a car with leather seats? (c) Interpret the slope in plain English.
Solution
(a) When leather = 0: \(\widehat{price} = 18.2 + 4.7(0) = 18.2\) thousand dollars, i.e. \$18,200.
(b) When leather = 1: \(\widehat{price} = 18.2 + 4.7(1) = 22.9\) thousand dollars, i.e. \$22,900.
(c) On average, used cars with leather seats sell for \$4,700 more than used cars without leather seats. The slope for a binary categorical predictor is the gap between the two group means.
Section Summary
- We define the best fit line as the line that minimizes the sum of the squared residuals (errors) about the line. That is, we find the line that minimizes \((y_{1} - \hat{y}_{1})^{2} + (y_{2} - \hat{y}_{2})^{2} + \cdots + (y_{n} - \hat{y}_{n})^{2} = \sum(y_{i} - \hat{y}_{i})^{2}\). We call this line the least squares regression line.
- We write the least squares regression line in the form \(\hat{y} = a + bx\), and we can calculate \(a\) and \(b\) based on the summary statistics as follows:
- Interpreting the slope and \(y\)-intercept of a linear model:
- The slope, \(b\), describes the average increase or decrease in the \(y\) variable if the explanatory variable \(x\) is one unit larger.
- The \(y\)-intercept, \(a\), describes the average or predicted outcome of \(y\) if \(x = 0\). The linear model must be valid all the way to \(x = 0\) for this to make sense, which in many applications is not the case.
- Two important considerations about the regression line:
- The regression line provides estimates or predictions, not actual values. It is important to know how large \(s\), the standard deviation of the residuals, is in order to know about how much error to expect in these predictions.
- The regression line estimates are only reasonable within the domain of the data. Predicting \(y\) for \(x\) values outside the domain — extrapolation — is unreliable and may produce ridiculous results.
- Using \(R^2\) to assess the fit of the model:
- \(R^{2}\), called R-squared or the explained variance, is a measure of how well the model explains or fits the data. \(R^{2}\) is always between 0 and 1, inclusive (or between 0% and 100%, inclusive). The higher the value of \(R^{2}\), the better the model "fits" the data.
- The \(R^{2}\) for a linear model describes the proportion of variation in the \(y\) variable that is explained by the regression line.
- \(R^{2}\) applies to any type of model, not just a linear model, and can be used to compare the fit among various models.
- The correlation \(r = -\sqrt{R^{2}}\) or \(r = \sqrt{R^{2}}\). The value of \(R^{2}\) is always positive and cannot tell us the direction of the association. If finding \(r\) based on \(R^{2}\), use either the scatterplot or the slope of the regression line to determine the sign of \(r\).
- When a residual plot of the data appears as a random cloud of points, a linear model is generally appropriate. If a residual plot has any type of pattern or curvature (such as a U-shape), a linear model is not appropriate.
- Outliers in regression are observations that fall far from the "cloud" of points.
- An influential point is a point that has a big effect or pull on the slope of the regression line. Points that are outliers in the \(x\) direction will have more pull on the slope of the regression line and are more likely to be influential points.
Problem Set
Source: Main Text
Problem 1: Units of regression. Consider a regression predicting weight (kg) from height (cm) for a sample of adult males. What are the units of the correlation coefficient, the intercept, and the slope?
Problem 8.17 Solution
Step 1 — Units of the correlation coefficient: The correlation coefficient \(r\) is computed from Z-scores, which have no units (Z-scores are dimensionless because they divide a length by a length, or a mass by a mass, etc.).
Step 2 — Units of the intercept: The intercept \(a\) is the predicted value of \(y\) when \(x = 0\). Here \(y\) is weight in kg, so the intercept has units of kg.
Step 3 — Units of the slope: The slope \(b\) is change in \(y\) per unit change in \(x\), so its units are "units of \(y\)" per "unit of \(x\)" — here, kg per cm (or kg/cm).
Answer: Correlation: unitless. Intercept: kg. Slope: kg/cm.
Problem 2: Which is higher? Determine if I or II is higher or if they are equal. Explain your reasoning. For a regression line, the uncertainty associated with the slope estimate, \(b\), is higher when:
I. there is a lot of scatter around the regression line, or II. there is very little scatter around the regression line.
Problem 8.18 Solution
Step 1 — Relate scatter to slope uncertainty: The standard error of the slope is roughly \(\text{SE}_b = s / (s_x \sqrt{n-1})\), where \(s\) is the standard deviation of the residuals. More scatter around the line means a larger \(s\), which means a larger SE, which means more uncertainty in the slope estimate.
Step 2 — Compare cases I and II: Case I (lots of scatter) produces a large \(s\) and thus a large \(\text{SE}_b\). Case II (little scatter) produces a small \(s\) and a small \(\text{SE}_b\).
Answer: I is higher. The slope estimate is less certain (larger standard error) when there is more scatter around the regression line.
Problem 3: Over-under, Part I. Suppose we fit a regression line to predict the shelf life of an apple based on its weight. For a particular apple, we predict the shelf life to be \(4.6\) days. The apple's residual is \(-0.6\) days. Did we over- or under-estimate the shelf-life of the apple? Explain your reasoning.
Problem 8.19 Solution
Step 1 — Recall the residual definition: \(\text{residual} = y - \hat{y}\), where \(y\) is the observed value and \(\hat{y}\) is the predicted value.
Step 2 — Solve for the observed \(y\): Given \(\hat{y} = 4.6\) and residual \(= -0.6\):
$$ y = \hat{y} + \text{residual} = 4.6 + (-0.6) = 4.0 \text{ days}. $$Step 3 — Compare prediction and observation: The prediction was 4.6 days but the actual shelf life was only 4.0 days. The predicted value was too high.
Answer: We over-estimated the shelf life. A negative residual always means the model predicted higher than the actual value.
Problem 4: Over-under, Part II. Suppose we fit a regression line to predict the number of incidents of skin cancer per 1,000 people from the number of sunny days in a year. For a particular year, we predict the incidence of skin cancer to be \(1.5\) per 1,000 people, and the residual for this year is \(0.5\). Did we over- or under-estimate the incidence of skin cancer? Explain your reasoning.
Problem 8.20 Solution
Step 1 — Solve for the observed \(y\): Given \(\hat{y} = 1.5\) per 1,000 people and residual \(= 0.5\):
$$ y = \hat{y} + \text{residual} = 1.5 + 0.5 = 2.0 \text{ per 1,000 people}. $$Step 2 — Compare prediction and observation: The prediction was 1.5 but the actual value was 2.0. The prediction was too low.
Answer: We under-estimated the incidence of skin cancer. A positive residual always means the model predicted lower than the actual value.
Problem 5: Tourism spending. The Association of Turkish Travel Agencies reports the number of foreign tourists visiting Turkey and tourist spending by year. Three plots are provided: scatterplot showing the relationship between these two variables along with the least squares fit, residuals plot, and histogram of residuals.
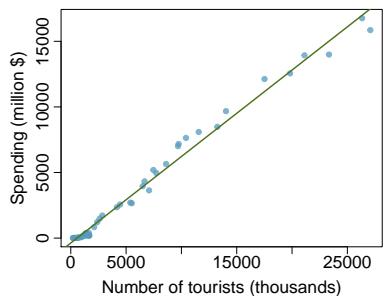
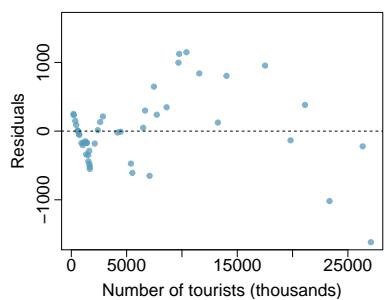
(a) Describe the relationship between number of tourists and spending. (b) What are the explanatory and response variables? (c) Why might we want to fit a regression line to these data? (d) Do the data meet the conditions required for fitting a least squares line? In addition to the scatterplot, use the residual plot and histogram to answer this question.
Problem 8.21 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a strong, positive, linear relationship between number of tourists and spending. As the number of tourists increases, tourist spending also increases in a roughly proportional way.
Step 2 — Identify variables (b): The explanatory (predictor) variable is the number of foreign tourists. The response variable is tourist spending. We use the number of tourists to predict or explain spending.
Step 3 — Reason for fitting a regression line (c): - Quantify the average spending per additional tourist (the slope). - Predict spending in a future year given a forecast of tourist numbers. - Summarize the relationship with a single equation suitable for reporting and planning.
Step 4 — Check conditions (d): The four conditions for least squares are (i) linearity — scatterplot roughly straight; (ii) nearly normal residuals — histogram of residuals roughly bell-shaped; (iii) constant variability — residual plot has roughly constant spread; (iv) independent observations. In a time-series of tourism years, independence is suspect (successive years are correlated). If the residual plot shows fanning or curvature, the constant-variability and linearity conditions would also fail.
Answer: (a) Strong positive linear. (b) Explanatory: number of tourists; response: spending. (c) To quantify and predict spending per tourist. (d) Conditions are mostly satisfied based on the three plots, but independence is questionable because data are collected over consecutive years. Any inferences should be made cautiously.
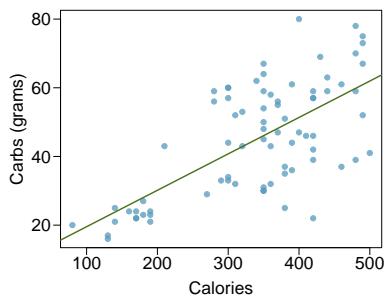
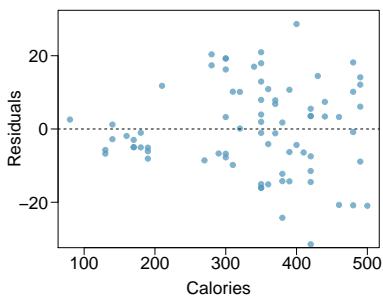
Problem 6: Nutrition at Starbucks, Part I. The scatterplot below shows the relationship between the number of calories and amount of carbohydrates (in grams) Starbucks food menu items contain. Since Starbucks only lists the number of calories on the display items, we are interested in predicting the amount of carbs a menu item has based on its calorie content.
(a) Describe the relationship between number of calories and amount of carbohydrates (in grams) that Starbucks food menu items contain. (b) In this scenario, what are the explanatory and response variables? (c) Why might we want to fit a regression line to these data? (d) Do these data meet the conditions required for fitting a least squares line?
Problem 8.22 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a moderate, positive, linear relationship between calories and carbohydrates. Items with more calories tend to contain more carbs. There is noticeable scatter because calories also come from fat and protein, not just carbs.
Step 2 — Identify variables (b): - Explanatory variable: calories (this is what Starbucks displays). - Response variable: amount of carbohydrates (what we want to predict).
Step 3 — Reason for fitting the line (c): A customer who knows only the calorie count (displayed prominently) can estimate how many carbs a menu item has — useful for diet tracking (e.g. diabetes, low-carb diets).
Step 4 — Check conditions (d): Using the scatterplot and residual plot: - Linearity: roughly satisfied — no obvious curve. - Constant variability: need to inspect the residual plot for fanning. Often these food-item plots show some fanning at higher calorie counts, which is a mild violation. - Nearly normal residuals: need the histogram — usually approximately symmetric. - Independence: the menu items are distinct food items, so independence is reasonable.
Answer: (a) Moderate positive linear. (b) Explanatory: calories; response: carbs. (c) To predict carbs from the posted calorie count. (d) Generally yes, with only mild concerns about constant variability.
Problem 7: The Coast Starlight, Part II. Exercise 8.11 introduces data on the Coast Starlight Amtrak train that runs from Seattle to Los Angeles. The mean travel time from one stop to the next on the Coast Starlight is 129 minutes, with a standard deviation of 113 minutes. The mean distance traveled from one stop to the next is 108 miles with a standard deviation of 99 miles. The correlation between travel time and distance is \(0.636\).
(a) Write the equation of the regression line for predicting travel time. (b) Interpret the slope and the intercept in this context. (c) Calculate \(R^{2}\) of the regression line for predicting travel time from distance traveled for the Coast Starlight, and interpret \(R^{2}\) in the context of the application. (d) The distance between Santa Barbara and Los Angeles is 103 miles. Use the model to estimate the time it takes for the Starlight to travel between these two cities. (e) It actually takes the Coast Starlight about 168 minutes to travel from Santa Barbara to Los Angeles. Calculate the residual and explain the meaning of this residual value. (f) Suppose Amtrak is considering adding a stop to the Coast Starlight 500 miles away from Los Angeles. Would it be appropriate to use this linear model to predict the travel time from Los Angeles to this point?
Problem 8.23 Solution
Step 1 — Write the regression equation (a): With \(\bar{x} = 108\) miles, \(\bar{y} = 129\) minutes, \(s_x = 99\), \(s_y = 113\), \(r = 0.636\):
$$ b = r\,\frac{s_y}{s_x} = 0.636 \cdot \frac{113}{99} = 0.636 \times 1.1414 \approx 0.726. $$ $$ a = \bar{y} - b\,\bar{x} = 129 - 0.726 \times 108 = 129 - 78.4 = 50.6. $$ $$ \widehat{\text{time}} = 50.6 + 0.726 \times \text{distance}. $$Step 2 — Interpret slope and intercept (b): - Slope (0.726 min/mile): For each additional mile between stops, the travel time increases by about 0.73 minutes on average (so about 82 mph = 1/0.726×60? actually speed is 60/0.726 ≈ 83 mph apparent speed addition, but interpretation is average time per extra mile). - Intercept (50.6 min): The predicted travel time when the distance is 0 miles is about 51 minutes. This has little practical meaning (no trip has distance 0), but it accounts for fixed time overhead (loading, unloading, acceleration).
Step 3 — Compute and interpret \(R^2\) (c):
$$ R^2 = r^2 = 0.636^2 = 0.4045 \approx 40.5\%. $$About 40.5% of the variability in travel time between stops is explained by the distance between them. The remaining 59.5% is due to grades, stops, track conditions, speed limits, etc.
Step 4 — Predict for 103 miles (d):
$$ \widehat{\text{time}} = 50.6 + 0.726 \times 103 = 50.6 + 74.78 = 125.4 \text{ minutes}. $$Step 5 — Compute residual (e):
$$ \text{residual} = 168 - 125.4 = 42.6 \text{ minutes}. $$The actual travel time exceeded the prediction by about 42.6 minutes. The model under-predicted this segment, likely because the route into Los Angeles has congestion or speed restrictions not captured by distance alone.
Step 6 — 500-mile extrapolation (f): The data's distances range roughly up to about a few hundred miles (based on the quoted mean 108 and sd 99). A 500-mile stretch would be far beyond the typical distance between stops, making this an extrapolation. It is not appropriate to use the model to predict travel time for a 500-mile segment.
Answer: (a) \(\widehat{\text{time}} = 50.6 + 0.726\,\text{distance}\). (b) Slope: +0.73 min/mile; intercept: ≈51 min (no practical meaning). (c) \(R^2 \approx 0.40\); 40% of variability explained. (d) ≈125 minutes. (e) Residual ≈ +42.6 min (under-predicted). (f) No — extrapolation well beyond data range.
Problem 8: Body measurements, Part III. Exercise 8.13 introduces data on shoulder girth and height of a group of individuals. The mean shoulder girth is 107.20 cm with a standard deviation of 10.37 cm. The mean height is 171.14 cm with a standard deviation of 9.41 cm. The correlation between height and shoulder girth is \(0.67\).
(a) Write the equation of the regression line for predicting height. (b) Interpret the slope and the intercept in this context. (c) Calculate \(R^{2}\) of the regression line for predicting height from shoulder girth, and interpret it in the context of the application. (d) A randomly selected student from your class has a shoulder girth of 100 cm. Predict the height of this student using the model. (e) The student from part (d) is 160 cm tall. Calculate the residual, and explain what this residual means. (f) A one year old has a shoulder girth of 56 cm. Would it be appropriate to use this linear model to predict the height of this child?
Problem 8.24 Solution
Step 1 — Write the regression equation (a): \(\bar{x} = 107.2\) (shoulder girth, cm), \(\bar{y} = 171.14\) (height, cm), \(s_x = 10.37\), \(s_y = 9.41\), \(r = 0.67\):
$$ b = r\,\frac{s_y}{s_x} = 0.67 \cdot \frac{9.41}{10.37} = 0.67 \times 0.9074 \approx 0.608. $$ $$ a = \bar{y} - b\,\bar{x} = 171.14 - 0.608 \times 107.2 = 171.14 - 65.18 = 105.96. $$ $$ \widehat{\text{height}} = 105.96 + 0.608 \times \text{shoulder\_girth}. $$Step 2 — Interpret coefficients (b): - Slope (0.608 cm/cm): For each additional 1 cm of shoulder girth, height increases by about 0.61 cm on average. - Intercept (105.96 cm): The predicted height when shoulder girth is 0 cm. Not meaningful in practice (no one has a shoulder girth of 0).
Step 3 — Compute \(R^2\) (c):
$$ R^2 = 0.67^2 = 0.4489 \approx 44.9\%. $$About 44.9% of the variation in height is explained by shoulder girth. The rest comes from other body-size and genetic factors.
Step 4 — Predict for 100 cm shoulder girth (d):
$$ \widehat{\text{height}} = 105.96 + 0.608 \times 100 = 105.96 + 60.8 = 166.76 \text{ cm}. $$Step 5 — Compute residual (e):
$$ \text{residual} = 160 - 166.76 = -6.76 \text{ cm}. $$The student is about 6.76 cm shorter than the model predicted. The model over-predicted this student's height by about 6.76 cm.
Step 6 — One-year-old shoulder girth of 56 cm (f): The sample's shoulder girths have mean 107.2 cm with sd 10.37 — a one-year-old's 56 cm is about \((56 - 107.2)/10.37 \approx -4.9\) standard deviations below the mean, well outside the data range. Also, the sample was of adults, not infants. Using the model for a one-year-old would be extrapolation and not appropriate.
Answer: (a) \(\widehat{\text{height}} = 105.96 + 0.608\,\text{shoulder\_girth}\). (b) Slope: 0.61 cm per cm; intercept: 105.96 cm (no practical meaning). (c) \(R^2 \approx 0.45\). (d) ≈166.76 cm. (e) Residual ≈ −6.76 cm (over-predicted). (f) No — extrapolation.
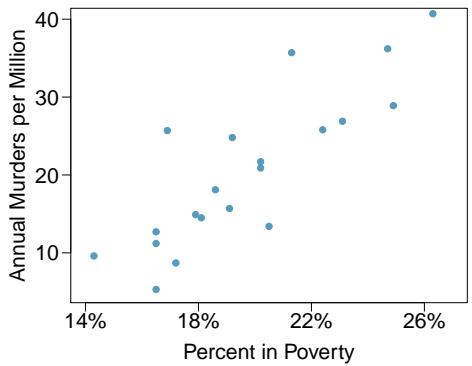
Problem 9: Murders and poverty, Part I. The following regression output is for predicting annual murders per million from percentage living in poverty in a random sample of 20 metropolitan areas.
| Estimate | Std. Error | t value | Pr(>|t|) | s = | |
| (Intercept) | -29.901 | 7.789 | -3.839 | 0.001 | |
| poverty% | 2.559 | 0.390 | 6.562 | 0.000 | |
| 5.512 | R² = 70.52% | R²adj = 68.89% | |||
(a) Write out the linear model. (b) Interpret the intercept. (c) Interpret the slope. (d) Interpret \(R^{2}\). (e) Calculate the correlation coefficient.
Problem 8.25 Solution
Step 1 — Write out the linear model (a):
From the regression output, intercept = \(-29.901\) and slope on poverty% = \(2.559\):
Step 2 — Interpret the intercept (b): The predicted annual murders per million when the poverty percentage is 0% is about \(-29.9\). A negative murder rate is impossible, so the intercept has no practical meaning here — no real area has 0% poverty, so \(x = 0\) is outside the data range (extrapolation).
Step 3 — Interpret the slope (c): For each additional 1 percentage point of population living in poverty, the annual murder rate increases by about 2.559 per million on average.
Step 4 — Interpret \(R^2\) (d): \(R^2 = 70.52\%\). About 70.5% of the variability in the annual murder rate across metro areas is explained by the poverty percentage. The remaining ~30% is explained by other factors (education, employment, population density, drug policy, etc.).
Step 5 — Compute the correlation coefficient (e): \(r = \pm \sqrt{R^2} = \pm \sqrt{0.7052} \approx \pm 0.8398\). The slope is positive (\(b = 2.559 > 0\)), so:
$$ r \approx +0.840. $$Answer: (a) \(\widehat{\text{murders}} = -29.901 + 2.559\,\text{poverty\%}\). (b) Intercept has no practical meaning (extrapolation). (c) +2.559 murders/million per 1 pp increase in poverty. (d) 70.5% of variability explained. (e) \(r \approx +0.840\).
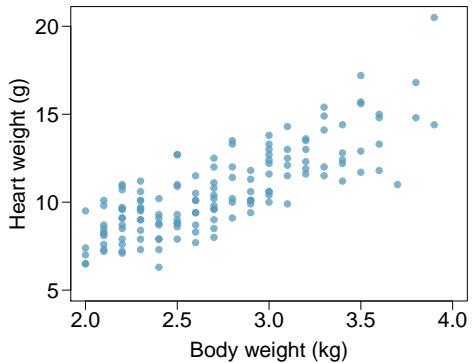
Problem 10: Cats, Part I. The following regression output is for predicting the heart weight (in g) of cats from their body weight (in kg). The coefficients are estimated using a dataset of 144 domestic cats.
| Estimate | Std. Error | t value | Pr(>|t|) | s = | |
| (Intercept) | -0.357 | 0.692 | -0.515 | 0.607 | |
| body wt | 4.034 | 0.250 | 16.119 | 0.000 | |
| 1.452 | R² = 64.66% | Radj² = 64.41% | |||
(a) Write out the linear model. (b) Interpret the intercept. (c) Interpret the slope. (d) Interpret \(R^{2}\). (e) Calculate the correlation coefficient.
Problem 8.26 Solution
Step 1 — Write out the linear model (a):
$$ \widehat{\text{heart\_wt}} = -0.357 + 4.034 \times \text{body\_wt}. $$Step 2 — Interpret the intercept (b): The predicted heart weight when a cat's body weight is 0 kg is \(-0.357\) g — impossible (body weight 0 means no cat), so the intercept is not meaningful practically. It is a mathematical artifact.
Step 3 — Interpret the slope (c): For each additional kilogram of body weight, a cat's heart weight increases by about 4.034 grams on average. This is a very strong, positive, physically sensible relationship.
Step 4 — Interpret \(R^2\) (d): \(R^2 = 64.66\%\). About 65% of the variability in cats' heart weights is explained by body weight. The rest is due to breed, age, sex, fitness, etc.
Step 5 — Compute the correlation (e): \(r = \pm \sqrt{0.6466} \approx \pm 0.804\). Slope is positive (+4.034), so:
$$ r \approx +0.804. $$Answer: (a) \(\widehat{\text{heart\_wt}} = -0.357 + 4.034\,\text{body\_wt}\). (b) Intercept not meaningful. (c) Heart weight increases by about 4.03 g per kg of body weight. (d) \(R^2 \approx 65\%\) — 65% of variability in heart weight explained by body weight. (e) \(r \approx +0.804\).
Problem 11: Outliers, Part I. Identify the outliers in the scatterplots shown below, and determine what type of outliers they are. Explain your reasoning.
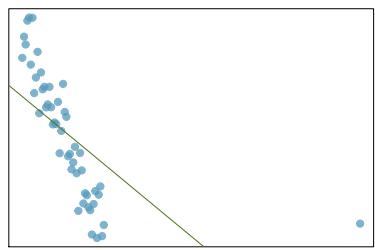
(a)
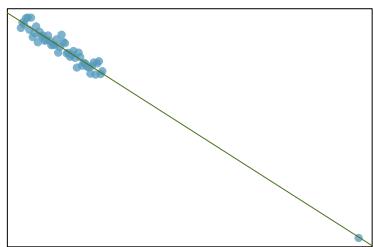
(b)
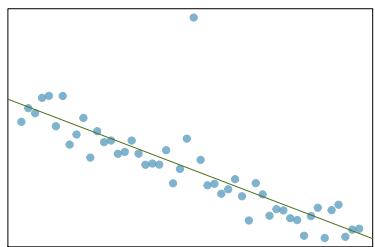
(c)
Problem 8.27 Solution
Step 1 — Outlier-type framework: Every outlier can be classified in two dimensions: - High leverage means the point has an \(x\)-value far from the rest of the data. - Influential means removing the point would noticeably change the slope or intercept. - Large residual only means the point is vertically far from the line but has an \(x\) near the center — it does not have much pull on the slope.
Step 2 — Typical answers for three panels: - (a) A point far to the right of the cloud, on the line → high leverage, not influential. - (b) A point in the middle of the \(x\) range but far above the line → large residual, not high leverage, not very influential (slope barely changes). - (c) A point far to the right of the cloud and far from the line → high leverage AND influential.
Answer: (a) High leverage, not influential. (b) Large residual, not high leverage, minimally influential. (c) High leverage AND influential — this point pulls the slope noticeably.
Problem 12: Outliers, Part II. Identify the outliers in the scatterplots shown below and determine what type of outliers they are. Explain your reasoning.
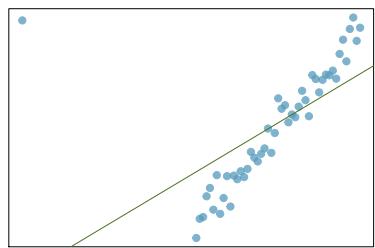
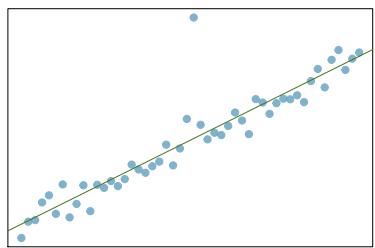
(a)

(b)
(c)
Problem 8.28 Solution
Step 1 — Reapply the outlier-type framework from Problem 8.27.
Step 2 — Typical answers for three panels: - (a) A point in the middle of the \(x\) range but far below the line → large residual, low leverage, low influence. - (b) A point far to the right, off the line → high leverage AND influential. - (c) A small cluster of points off to one side (e.g. far right) → collectively high leverage and influential; the cluster shifts the regression line.
Answer: (a) Large residual, low leverage, low influence. (b) High leverage AND influential. (c) The cluster acts as a collective high-leverage, influential group.
Problem 13: Urban homeowners, Part I. The scatterplot below shows the percent of families who own their home vs. the percent of the population living in urban areas. There are 52 observations, each corresponding to a state in the US. Puerto Rico and District of Columbia are also included.
(a) Describe the relationship between the percent of families who own their home and the percent of the population living in urban areas. (b) The outlier at the bottom right corner is District of Columbia, where \(100\%\) of the population is considered urban. What type of an outlier is this observation?
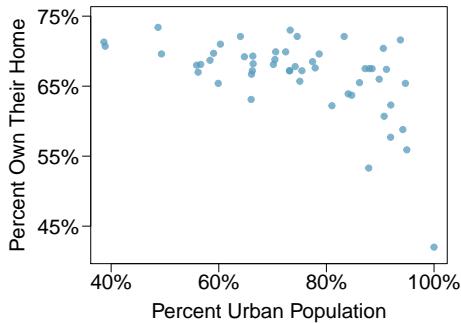
Problem 8.29 Solution
Step 1 — Describe the relationship (a): The scatterplot shows a moderate negative linear relationship: states with a higher percentage of urban population tend to have a lower percentage of families owning their home. Apartments are more common in urban areas, driving down ownership rates.
Step 2 — Classify the District of Columbia outlier (b): DC sits at the far right (100% urban) with a much lower homeownership percentage than the trend would predict. Its \(x\)-value is far from the center of the \(x\) distribution → high leverage. It also falls well away from the regression line the other 51 observations would produce → influential. DC is therefore both an outlier with high leverage and an influential point.
Answer: (a) Moderate negative linear — more urban means less ownership. (b) DC is a high-leverage, influential outlier.
Problem 14: Crawling babies, Part II. Exercise 8.12 introduces data on the average monthly temperature during the month babies first try to crawl (about 6 months after birth) and the average first crawling age for babies born in a given month. A scatterplot of these two variables reveals a potential outlying month when the average temperature is about \(53^{\circ}\text{F}\) and average crawling age is about 28.5 weeks. Does this point have high leverage? Is it an influential point?
Problem 8.30 Solution
Step 1 — Recall the Crawling Babies setup: The study has 12 data points (one per birth month). The outlying month has \(x = 53^\circ\text{F}\) and \(y = 28.5\) weeks.
Step 2 — Is it high leverage? The mean temperature across the 12 months is somewhere in the middle of the observed range (probably around 50–60°F). An \(x\)-value of 53°F is close to the center of the \(x\) distribution, not far from the \(\bar{x}\). Therefore this point does NOT have high leverage.
Step 3 — Is it influential? An influential point requires both (a) high leverage and (b) removal would noticeably change the regression line's slope/intercept. Since this point does not have high leverage, it cannot be strongly influential — removing it would barely move the slope. However, it is a point with an unusually large residual (vertical distance from the line).
Answer: No, it does not have high leverage, and it is not influential. It is just an observation with a large residual — a point that is vertically far from the line but whose \(x\)-value is near the middle of the data, so it cannot pull the slope in either direction.